%pip install polars seaborn matplotlib huggingface_hub How Fine is FineWeb2?
polars
huggingface
fineweb
Analysis of the FineWeb-C dataset
Recently FineWeb2 was released, adding multilingual data to the original FineWeb dataset. As part of the FineWeb-C community initiative, contributors have been annotating samples from this dataset to assess educational quality across different languages.
The goal of this effort is to reproduce something similar to the original FineWeb-Edu dataset for all languages. You can read more about why this is important in the FineWeb-C blog post.
Analyzing the FineWeb-C Community Annotations
This post examines the annotation data collected so far through the FineWeb-C project. For most languages, community members have annotated random samples of approximately 1,000 examples from FineWeb2. The annotations focus on:
- Educational value assessment
- Language identification verification
- Problematic content flagging
Let’s explore what the community annotations tell us about the quality and characteristics of content across different languages in FineWeb2.
We’ll start by installing the necessary libraries.
import polars as pl
from huggingface_hub import list_repo_files
# bump up the number of rows in the polars table so we can see more data
pl.Config.set_tbl_rows(100)We’ll use Polars to load the annotations but we could also load in Pandas, Dask, DuckDB, PySpark, or the Hugging Face Datasets library!
The fineweb-c dataset has a config per language but also a general config. We’ll load all the parquet files for each language, which we can get using the list_repo_files function from the huggingface_hub library.
paths = list_repo_files("data-is-better-together/fineweb-c", repo_type="dataset")
paths = [f for f in paths if f.endswith(".parquet") and "data" not in f]
paths['aeb_Arab/train-00000-of-00001.parquet',
'apc_Arab/train-00000-of-00001.parquet',
'arb_Arab/train-00000-of-00001.parquet',
'ars_Arab/train-00000-of-00001.parquet',
'ary_Arab/train-00000-of-00001.parquet',
'arz_Arab/train-00000-of-00001.parquet',
'asm_Beng/train-00000-of-00001.parquet',
'asm_Latn/train-00000-of-00001.parquet',
'ast_Latn/train-00000-of-00001.parquet',
'bak_Cyrl/train-00000-of-00001.parquet',
'bar_Latn/train-00000-of-00001.parquet',
'ben_Beng/train-00000-of-00001.parquet',
'bho_Deva/train-00000-of-00001.parquet',
'bre_Latn/train-00000-of-00001.parquet',
'bul_Cyrl/train-00000-of-00001.parquet',
'cat_Latn/train-00000-of-00001.parquet',
'ces_Latn/train-00000-of-00001.parquet',
'cmn_Hani/train-00000-of-00001.parquet',
'crh_Latn/train-00000-of-00001.parquet',
'dan_Latn/train-00000-of-00001.parquet',
'deu_Latn/train-00000-of-00001.parquet',
'ekk_Latn/train-00000-of-00001.parquet',
'eus_Latn/train-00000-of-00001.parquet',
'fao_Latn/train-00000-of-00001.parquet',
'fas_Arab/train-00000-of-00001.parquet',
'fil_Latn/train-00000-of-00001.parquet',
'fin_Latn/train-00000-of-00001.parquet',
'fra_Latn/train-00000-of-00001.parquet',
'glg_Latn/train-00000-of-00001.parquet',
'gmh_Latn/train-00000-of-00001.parquet',
'goh_Latn/train-00000-of-00001.parquet',
'gom_Deva/train-00000-of-00001.parquet',
'gsw_Latn/train-00000-of-00001.parquet',
'guj_Gujr/train-00000-of-00001.parquet',
'hin_Deva/train-00000-of-00001.parquet',
'hsb_Latn/train-00000-of-00001.parquet',
'hun_Latn/train-00000-of-00001.parquet',
'ind_Latn/train-00000-of-00001.parquet',
'ita_Latn/train-00000-of-00001.parquet',
'jpn_Jpan/train-00000-of-00001.parquet',
'kas_Deva/train-00000-of-00001.parquet',
'kin_Latn/train-00000-of-00001.parquet',
'kor_Hang/train-00000-of-00001.parquet',
'lat_Latn/train-00000-of-00001.parquet',
'lez_Cyrl/train-00000-of-00001.parquet',
'lij_Latn/train-00000-of-00001.parquet',
'lit_Latn/train-00000-of-00001.parquet',
'lug_Latn/train-00000-of-00001.parquet',
'lvs_Latn/train-00000-of-00001.parquet',
'mal_Mlym/train-00000-of-00001.parquet',
'mar_Deva/train-00000-of-00001.parquet',
'nan_Latn/train-00000-of-00001.parquet',
'nds_Latn/train-00000-of-00001.parquet',
'nld_Latn/train-00000-of-00001.parquet',
'nob_Latn/train-00000-of-00001.parquet',
'npi_Deva/train-00000-of-00001.parquet',
'npi_Latn/train-00000-of-00001.parquet',
'pbt_Arab/train-00000-of-00001.parquet',
'pcm_Latn/train-00000-of-00001.parquet',
'pdc_Latn/train-00000-of-00001.parquet',
'pfl_Latn/train-00000-of-00001.parquet',
'pol_Latn/train-00000-of-00001.parquet',
'por_Latn/train-00000-of-00001.parquet',
'quz_Latn/train-00000-of-00001.parquet',
'ron_Latn/train-00000-of-00001.parquet',
'rus_Cyrl/train-00000-of-00001.parquet',
'sco_Latn/train-00000-of-00001.parquet',
'sin_Sinh/train-00000-of-00001.parquet',
'slk_Latn/train-00000-of-00001.parquet',
'som_Latn/train-00000-of-00001.parquet',
'spa_Latn/train-00000-of-00001.parquet',
'srp_Cyrl/train-00000-of-00001.parquet',
'srp_Latn/train-00000-of-00001.parquet',
'swe_Latn/train-00000-of-00001.parquet',
'tam_Taml/train-00000-of-00001.parquet',
'tat_Cyrl/train-00000-of-00001.parquet',
'tat_Latn/train-00000-of-00001.parquet',
'tel_Telu/train-00000-of-00001.parquet',
'tha_Thai/train-00000-of-00001.parquet',
'tir_Ethi/train-00000-of-00001.parquet',
'tok_Latn/train-00000-of-00001.parquet',
'tur_Latn/train-00000-of-00001.parquet',
'udm_Cyrl/train-00000-of-00001.parquet',
'ukr_Cyrl/train-00000-of-00001.parquet',
'uzn_Cyrl/train-00000-of-00001.parquet',
'uzn_Latn/train-00000-of-00001.parquet',
'vie_Latn/train-00000-of-00001.parquet',
'vls_Latn/train-00000-of-00001.parquet',
'yor_Latn/train-00000-of-00001.parquet',
'yue_Hani/train-00000-of-00001.parquet',
'zsm_Latn/train-00000-of-00001.parquet']keep_columns = [
"id",
"text",
"educational_value_labels",
"annotator_ids",
"problematic_content_label_present",
"problematic_content_label_agreement",
"language_names",
"language_code",
]df = pl.scan_parquet(
[f"hf://datasets/data-is-better-together/fineweb-c/{p}" for p in paths]
).select(keep_columns)
df.sink_parquet("fineweb-c-annotations.parquet")
df = pl.scan_parquet("fineweb-c-annotations.parquet")How many languages are included in the dataset so far?
df.select(pl.col("language_code")).unique().collect().count()
shape: (1, 1)
| language_code |
|---|
| u32 |
| 91 |
We can also see how many rows there are per language.
df.group_by(["language_code"]).agg(pl.col("id").len().alias("n_rows")).sort(
"n_rows", descending=True
).collect()
shape: (91, 2)
| language_code | n_rows |
|---|---|
| str | u32 |
| "tat_Cyrl" | 1557 |
| "lij_Latn" | 1000 |
| "vie_Latn" | 1000 |
| "dan_Latn" | 1000 |
| "spa_Latn" | 1000 |
| "jpn_Jpan" | 1000 |
| "yue_Hani" | 1000 |
| "ukr_Cyrl" | 1000 |
| "ary_Arab" | 1000 |
| "asm_Latn" | 1000 |
| "arz_Arab" | 1000 |
| "swe_Latn" | 1000 |
| "arb_Arab" | 1000 |
| "fas_Arab" | 1000 |
| "vls_Latn" | 1000 |
| "fra_Latn" | 1000 |
| "ita_Latn" | 1000 |
| "rus_Cyrl" | 1000 |
| "pfl_Latn" | 1000 |
| "bar_Latn" | 1000 |
| "goh_Latn" | 1000 |
| "fin_Latn" | 1000 |
| "gmh_Latn" | 1000 |
| "ars_Arab" | 1000 |
| "zsm_Latn" | 1000 |
| "fil_Latn" | 1000 |
| "gsw_Latn" | 1000 |
| "tam_Taml" | 1000 |
| "hin_Deva" | 1000 |
| "cmn_Hani" | 1000 |
| "kin_Latn" | 912 |
| "tir_Ethi" | 745 |
| "bho_Deva" | 643 |
| "kor_Hang" | 639 |
| "pdc_Latn" | 622 |
| "sco_Latn" | 588 |
| "aeb_Arab" | 529 |
| "ces_Latn" | 459 |
| "yor_Latn" | 443 |
| "bak_Cyrl" | 442 |
| "tha_Thai" | 411 |
| "por_Latn" | 404 |
| "nds_Latn" | 389 |
| "npi_Deva" | 387 |
| "tur_Latn" | 379 |
| "nld_Latn" | 361 |
| "glg_Latn" | 341 |
| "lit_Latn" | 323 |
| "ron_Latn" | 268 |
| "apc_Arab" | 250 |
| "eus_Latn" | 246 |
| "pcm_Latn" | 240 |
| "slk_Latn" | 221 |
| "deu_Latn" | 212 |
| "sin_Sinh" | 211 |
| "tat_Latn" | 208 |
| "crh_Latn" | 188 |
| "kas_Deva" | 186 |
| "gom_Deva" | 160 |
| "lat_Latn" | 149 |
| "ekk_Latn" | 141 |
| "lug_Latn" | 132 |
| "hun_Latn" | 124 |
| "srp_Cyrl" | 93 |
| "ast_Latn" | 80 |
| "lvs_Latn" | 80 |
| "quz_Latn" | 80 |
| "tel_Telu" | 66 |
| "mar_Deva" | 56 |
| "udm_Cyrl" | 55 |
| "lez_Cyrl" | 55 |
| "pol_Latn" | 50 |
| "bre_Latn" | 46 |
| "uzn_Latn" | 44 |
| "bul_Cyrl" | 36 |
| "cat_Latn" | 34 |
| "ind_Latn" | 29 |
| "hsb_Latn" | 27 |
| "asm_Beng" | 24 |
| "nob_Latn" | 24 |
| "fao_Latn" | 24 |
| "uzn_Cyrl" | 20 |
| "ben_Beng" | 15 |
| "nan_Latn" | 14 |
| "npi_Latn" | 12 |
| "tok_Latn" | 11 |
| "som_Latn" | 11 |
| "srp_Latn" | 11 |
| "guj_Gujr" | 11 |
| "pbt_Arab" | 11 |
| "mal_Mlym" | 10 |
We could also directly use the datasets viewer to get this information! This can be a really useful way to explore the data very quickly without having to load it locally.
Number of annotators
Since starting this project we’ve found some languages have had more problematic data, including languages where a lot of data was identified in the wrong language. Because of this for some languages we’ve set a higher or lower “retirement” threshold before retiring a sample. This means some languages have only a single annotator labeling each example whilst others have had multiple people annotate each example.
Let’s look at the mean number of annotators per language.
df.group_by(["language_code"]).agg(
pl.col("educational_value_labels").list.len().mean().alias("n_annotators")
).sort("n_annotators", descending=True).collect()
shape: (91, 2)
| language_code | n_annotators |
|---|---|
| str | f64 |
| "vie_Latn" | 2.869 |
| "dan_Latn" | 2.573 |
| "tir_Ethi" | 2.126174 |
| "spa_Latn" | 2.126 |
| "deu_Latn" | 2.037736 |
| "ita_Latn" | 2.006 |
| "bak_Cyrl" | 2.002262 |
| "slk_Latn" | 2.0 |
| "lvs_Latn" | 2.0 |
| "eus_Latn" | 1.166667 |
| "ary_Arab" | 1.019 |
| "fin_Latn" | 1.017 |
| "fra_Latn" | 1.012 |
| "arz_Arab" | 1.006 |
| "swe_Latn" | 1.006 |
| "nds_Latn" | 1.005141 |
| "rus_Cyrl" | 1.003 |
| "tat_Cyrl" | 1.002569 |
| "arb_Arab" | 1.002 |
| "asm_Latn" | 1.002 |
| "tam_Taml" | 1.002 |
| "fas_Arab" | 1.001 |
| "nld_Latn" | 1.0 |
| "uzn_Latn" | 1.0 |
| "guj_Gujr" | 1.0 |
| "cat_Latn" | 1.0 |
| "cmn_Hani" | 1.0 |
| "uzn_Cyrl" | 1.0 |
| "ben_Beng" | 1.0 |
| "hsb_Latn" | 1.0 |
| "bul_Cyrl" | 1.0 |
| "ces_Latn" | 1.0 |
| "tel_Telu" | 1.0 |
| "bre_Latn" | 1.0 |
| "npi_Latn" | 1.0 |
| "crh_Latn" | 1.0 |
| "zsm_Latn" | 1.0 |
| "tur_Latn" | 1.0 |
| "srp_Cyrl" | 1.0 |
| "lat_Latn" | 1.0 |
| "yue_Hani" | 1.0 |
| "asm_Beng" | 1.0 |
| "pbt_Arab" | 1.0 |
| "bar_Latn" | 1.0 |
| "tha_Thai" | 1.0 |
| "kor_Hang" | 1.0 |
| "goh_Latn" | 1.0 |
| "sin_Sinh" | 1.0 |
| "lug_Latn" | 1.0 |
| "mar_Deva" | 1.0 |
| "mal_Mlym" | 1.0 |
| "ars_Arab" | 1.0 |
| "ukr_Cyrl" | 1.0 |
| "vls_Latn" | 1.0 |
| "npi_Deva" | 1.0 |
| "aeb_Arab" | 1.0 |
| "kas_Deva" | 1.0 |
| "ekk_Latn" | 1.0 |
| "som_Latn" | 1.0 |
| "lit_Latn" | 1.0 |
| "srp_Latn" | 1.0 |
| "kin_Latn" | 1.0 |
| "apc_Arab" | 1.0 |
| "ron_Latn" | 1.0 |
| "hin_Deva" | 1.0 |
| "pdc_Latn" | 1.0 |
| "bho_Deva" | 1.0 |
| "ind_Latn" | 1.0 |
| "lez_Cyrl" | 1.0 |
| "udm_Cyrl" | 1.0 |
| "sco_Latn" | 1.0 |
| "quz_Latn" | 1.0 |
| "pol_Latn" | 1.0 |
| "pcm_Latn" | 1.0 |
| "tat_Latn" | 1.0 |
| "jpn_Jpan" | 1.0 |
| "hun_Latn" | 1.0 |
| "pfl_Latn" | 1.0 |
| "lij_Latn" | 1.0 |
| "yor_Latn" | 1.0 |
| "fao_Latn" | 1.0 |
| "nan_Latn" | 1.0 |
| "ast_Latn" | 1.0 |
| "gmh_Latn" | 1.0 |
| "nob_Latn" | 1.0 |
| "fil_Latn" | 1.0 |
| "gom_Deva" | 1.0 |
| "glg_Latn" | 1.0 |
| "tok_Latn" | 1.0 |
| "por_Latn" | 1.0 |
| "gsw_Latn" | 1.0 |
Ideally as we progress with the project we’ll increase the overlap at least for some time to see how much annotators agree (more on this below) but we also don’t want people to spend a lot of time annotating the same sample if it’s of low quality.
Look at the distribution of labels
No we’ve got a sense of how many annotators there are per language, let’s look at the distribution of labels. Since we sometimes have multiple labels for each sample we’ll simplify things a bit to just look at the first label for each sample. For some languages this will be the only label anyway. If we work with a specific language for a longer time we’ll also want to consider the agreement between annotators.
df = df.with_columns(
pl.col("educational_value_labels").list.first().alias("label")
).collect()
df.head(1)
shape: (1, 9)
| id | text | educational_value_labels | annotator_ids | problematic_content_label_present | problematic_content_label_agreement | language_names | language_code | label |
|---|---|---|---|---|---|---|---|---|
| str | str | list[str] | list[str] | bool | f64 | str | str | str |
| "3b69c85c-29ec-4f01-a0dd-49ed1b… | "نجمة في السما ولمرورك لدينا كا… | ["None"] | ["73ee8b99-a3f3-484b-bccf-7874521a5bc7"] | false | 1.0 | "aeb_Arab" | "aeb_Arab" | "None" |
Click to show/hide code
label_counts = (
df.group_by(["language_code", "label"])
.len()
.pivot(
values="len",
index="language_code",
on="label",
aggregate_function="sum",
)
.fill_null(0)
)
# Calculate row totals
row_totals = label_counts.select(pl.exclude("language_code")).sum_horizontal()
# Calculate percentages
label_percentages = (
label_counts.with_columns(
pl.col(col) / row_totals * 100
for col in label_counts.columns
if col != "language_code"
)
.select(["language_code", pl.all().exclude("language_code").round(2)])
.sort("language_code")
)
label_percentages
shape: (91, 8)
| language_code | Good | Basic | ❗ Problematic Content ❗ | None | Minimal | ❗ Wrong language ❗ | Excellent |
|---|---|---|---|---|---|---|---|
| str | f64 | f64 | f64 | f64 | f64 | f64 | f64 |
| "aeb_Arab" | 0.57 | 4.16 | 12.48 | 77.69 | 4.73 | 0.0 | 0.38 |
| "apc_Arab" | 2.4 | 2.4 | 80.0 | 12.0 | 2.0 | 0.0 | 1.2 |
| "arb_Arab" | 2.5 | 4.9 | 25.3 | 51.0 | 15.6 | 0.0 | 0.7 |
| "ars_Arab" | 0.6 | 1.9 | 15.5 | 69.9 | 10.5 | 1.4 | 0.2 |
| "ary_Arab" | 1.4 | 0.7 | 94.6 | 1.1 | 1.2 | 0.0 | 1.0 |
| "arz_Arab" | 4.0 | 4.1 | 73.5 | 12.7 | 3.7 | 0.0 | 2.0 |
| "asm_Beng" | 12.5 | 8.33 | 0.0 | 37.5 | 12.5 | 0.0 | 29.17 |
| "asm_Latn" | 0.0 | 0.3 | 19.1 | 64.7 | 5.0 | 10.9 | 0.0 |
| "ast_Latn" | 12.5 | 17.5 | 7.5 | 30.0 | 28.75 | 3.75 | 0.0 |
| "bak_Cyrl" | 1.13 | 4.75 | 4.3 | 75.11 | 14.48 | 0.0 | 0.23 |
| "bar_Latn" | 0.0 | 4.1 | 77.0 | 16.5 | 2.4 | 0.0 | 0.0 |
| "ben_Beng" | 6.67 | 0.0 | 6.67 | 60.0 | 20.0 | 6.67 | 0.0 |
| "bho_Deva" | 3.11 | 5.29 | 7.93 | 69.67 | 13.84 | 0.0 | 0.16 |
| "bre_Latn" | 2.17 | 2.17 | 91.3 | 2.17 | 2.17 | 0.0 | 0.0 |
| "bul_Cyrl" | 11.11 | 19.44 | 8.33 | 19.44 | 33.33 | 0.0 | 8.33 |
| "cat_Latn" | 8.82 | 17.65 | 0.0 | 32.35 | 41.18 | 0.0 | 0.0 |
| "ces_Latn" | 1.96 | 7.63 | 1.96 | 73.64 | 14.38 | 0.44 | 0.0 |
| "cmn_Hani" | 9.7 | 25.1 | 2.5 | 24.2 | 36.2 | 0.9 | 1.4 |
| "crh_Latn" | 0.0 | 0.53 | 96.28 | 0.53 | 2.13 | 0.0 | 0.53 |
| "dan_Latn" | 1.2 | 8.4 | 14.5 | 47.6 | 28.2 | 0.0 | 0.1 |
| "deu_Latn" | 9.43 | 14.62 | 3.3 | 45.28 | 22.64 | 0.0 | 4.72 |
| "ekk_Latn" | 2.13 | 12.77 | 17.02 | 38.3 | 29.79 | 0.0 | 0.0 |
| "eus_Latn" | 6.91 | 10.57 | 12.6 | 44.31 | 24.39 | 0.0 | 1.22 |
| "fao_Latn" | 0.0 | 12.5 | 8.33 | 45.83 | 29.17 | 4.17 | 0.0 |
| "fas_Arab" | 8.9 | 10.0 | 20.5 | 39.6 | 18.7 | 0.0 | 2.3 |
| "fil_Latn" | 2.6 | 5.1 | 37.9 | 24.1 | 27.6 | 1.9 | 0.8 |
| "fin_Latn" | 18.2 | 20.6 | 8.5 | 19.7 | 28.5 | 1.9 | 2.6 |
| "fra_Latn" | 5.7 | 8.6 | 4.8 | 54.3 | 23.8 | 0.0 | 2.8 |
| "glg_Latn" | 5.28 | 10.85 | 2.05 | 54.84 | 24.93 | 0.0 | 2.05 |
| "gmh_Latn" | 0.0 | 0.2 | 98.3 | 1.0 | 0.5 | 0.0 | 0.0 |
| "goh_Latn" | 0.0 | 0.0 | 67.9 | 8.4 | 0.2 | 23.4 | 0.1 |
| "gom_Deva" | 0.0 | 0.0 | 100.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| "gsw_Latn" | 3.6 | 2.2 | 1.3 | 29.3 | 2.5 | 60.0 | 1.1 |
| "guj_Gujr" | 0.0 | 27.27 | 9.09 | 18.18 | 45.45 | 0.0 | 0.0 |
| "hin_Deva" | 0.2 | 0.9 | 0.3 | 87.1 | 11.2 | 0.0 | 0.3 |
| "hsb_Latn" | 25.93 | 33.33 | 0.0 | 14.81 | 18.52 | 3.7 | 3.7 |
| "hun_Latn" | 4.84 | 6.45 | 6.45 | 50.81 | 30.65 | 0.81 | 0.0 |
| "ind_Latn" | 6.9 | 6.9 | 44.83 | 31.03 | 10.34 | 0.0 | 0.0 |
| "ita_Latn" | 8.3 | 14.0 | 7.2 | 43.9 | 25.3 | 0.0 | 1.3 |
| "jpn_Jpan" | 0.7 | 3.8 | 4.6 | 76.7 | 13.9 | 0.1 | 0.2 |
| "kas_Deva" | 4.3 | 6.99 | 37.63 | 40.32 | 10.75 | 0.0 | 0.0 |
| "kin_Latn" | 13.49 | 20.94 | 0.88 | 33.88 | 20.83 | 0.0 | 9.98 |
| "kor_Hang" | 3.13 | 12.99 | 9.55 | 39.75 | 33.8 | 0.0 | 0.78 |
| "lat_Latn" | 0.0 | 0.0 | 4.03 | 95.3 | 0.67 | 0.0 | 0.0 |
| "lez_Cyrl" | 0.0 | 14.55 | 0.0 | 16.36 | 67.27 | 1.82 | 0.0 |
| "lij_Latn" | 0.4 | 0.5 | 13.2 | 5.6 | 1.7 | 78.4 | 0.2 |
| "lit_Latn" | 13.0 | 14.55 | 9.6 | 35.6 | 23.53 | 1.55 | 2.17 |
| "lug_Latn" | 1.52 | 6.06 | 27.27 | 28.79 | 32.58 | 3.03 | 0.76 |
| "lvs_Latn" | 3.75 | 6.25 | 15.0 | 60.0 | 15.0 | 0.0 | 0.0 |
| "mal_Mlym" | 50.0 | 0.0 | 10.0 | 20.0 | 10.0 | 10.0 | 0.0 |
| "mar_Deva" | 14.29 | 39.29 | 0.0 | 14.29 | 26.79 | 0.0 | 5.36 |
| "nan_Latn" | 0.0 | 14.29 | 14.29 | 0.0 | 14.29 | 50.0 | 7.14 |
| "nds_Latn" | 8.48 | 14.91 | 40.87 | 17.48 | 13.88 | 0.0 | 4.37 |
| "nld_Latn" | 6.37 | 14.96 | 3.88 | 44.04 | 29.09 | 0.0 | 1.66 |
| "nob_Latn" | 8.33 | 8.33 | 33.33 | 25.0 | 25.0 | 0.0 | 0.0 |
| "npi_Deva" | 70.54 | 10.85 | 0.26 | 14.47 | 2.84 | 0.0 | 1.03 |
| "npi_Latn" | 0.0 | 8.33 | 8.33 | 16.67 | 58.33 | 8.33 | 0.0 |
| "pbt_Arab" | 9.09 | 0.0 | 0.0 | 0.0 | 90.91 | 0.0 | 0.0 |
| "pcm_Latn" | 0.0 | 0.0 | 62.92 | 3.33 | 0.83 | 32.92 | 0.0 |
| "pdc_Latn" | 0.0 | 0.0 | 100.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| "pfl_Latn" | 0.0 | 1.1 | 87.2 | 8.2 | 3.3 | 0.2 | 0.0 |
| "pol_Latn" | 2.0 | 8.0 | 8.0 | 58.0 | 24.0 | 0.0 | 0.0 |
| "por_Latn" | 5.2 | 9.9 | 5.94 | 60.15 | 16.58 | 0.0 | 2.23 |
| "quz_Latn" | 0.0 | 0.0 | 0.0 | 26.25 | 60.0 | 13.75 | 0.0 |
| "ron_Latn" | 2.99 | 5.22 | 5.6 | 63.81 | 20.9 | 0.0 | 1.49 |
| "rus_Cyrl" | 3.0 | 6.1 | 7.6 | 68.3 | 13.9 | 0.0 | 1.1 |
| "sco_Latn" | 1.36 | 4.08 | 81.63 | 7.82 | 5.1 | 0.0 | 0.0 |
| "sin_Sinh" | 4.27 | 12.32 | 5.21 | 16.59 | 60.19 | 1.42 | 0.0 |
| "slk_Latn" | 3.17 | 7.69 | 4.52 | 60.18 | 22.17 | 0.0 | 2.26 |
| "som_Latn" | 36.36 | 45.45 | 0.0 | 0.0 | 9.09 | 0.0 | 9.09 |
| "spa_Latn" | 2.9 | 7.3 | 3.9 | 60.7 | 24.5 | 0.0 | 0.7 |
| "srp_Cyrl" | 16.13 | 23.66 | 17.2 | 7.53 | 34.41 | 0.0 | 1.08 |
| "srp_Latn" | 0.0 | 18.18 | 0.0 | 63.64 | 18.18 | 0.0 | 0.0 |
| "swe_Latn" | 3.3 | 8.5 | 8.5 | 54.5 | 24.1 | 0.0 | 1.1 |
| "tam_Taml" | 1.6 | 5.0 | 5.3 | 73.7 | 14.3 | 0.0 | 0.1 |
| "tat_Cyrl" | 3.85 | 33.78 | 2.5 | 36.61 | 21.97 | 0.0 | 1.28 |
| "tat_Latn" | 2.4 | 22.6 | 6.73 | 43.27 | 23.56 | 1.44 | 0.0 |
| "tel_Telu" | 22.73 | 16.67 | 1.52 | 25.76 | 27.27 | 0.0 | 6.06 |
| "tha_Thai" | 7.06 | 10.22 | 29.93 | 32.6 | 19.71 | 0.0 | 0.49 |
| "tir_Ethi" | 7.92 | 13.83 | 17.45 | 25.5 | 30.74 | 0.0 | 4.56 |
| "tok_Latn" | 9.09 | 36.36 | 18.18 | 9.09 | 9.09 | 18.18 | 0.0 |
| "tur_Latn" | 19.26 | 20.05 | 7.92 | 9.76 | 35.62 | 0.0 | 7.39 |
| "udm_Cyrl" | 1.82 | 12.73 | 0.0 | 7.27 | 76.36 | 1.82 | 0.0 |
| "ukr_Cyrl" | 7.7 | 6.4 | 1.4 | 73.6 | 8.6 | 0.0 | 2.3 |
| "uzn_Cyrl" | 15.0 | 30.0 | 0.0 | 0.0 | 45.0 | 0.0 | 10.0 |
| "uzn_Latn" | 20.45 | 27.27 | 4.55 | 4.55 | 43.18 | 0.0 | 0.0 |
| "vie_Latn" | 6.4 | 13.1 | 9.5 | 35.9 | 33.9 | 0.0 | 1.2 |
| "vls_Latn" | 0.2 | 15.1 | 79.1 | 3.9 | 1.7 | 0.0 | 0.0 |
| "yor_Latn" | 5.64 | 9.71 | 26.41 | 29.12 | 24.15 | 0.0 | 4.97 |
| "yue_Hani" | 5.5 | 9.6 | 0.9 | 68.4 | 13.8 | 0.0 | 1.8 |
| "zsm_Latn" | 4.5 | 10.1 | 0.4 | 44.9 | 37.3 | 0.1 | 2.7 |
This is a bit hard to read so let’s plot it as a heatmap.
Click to show/hide code
import matplotlib.pyplot as plt
import seaborn as sns
# Convert Polars DataFrame to pandas for seaborn
label_percentages_pd = label_percentages.to_pandas()
# Clean up column names by replacing the problematic symbols
label_percentages_pd.columns = [
col.replace("❗", "!") for col in label_percentages_pd.columns
]
# Define the desired column order
column_order = [
"! Problematic Content !",
"! Wrong language !",
"None",
"Basic",
"Minimal",
"Good",
"Excellent",
]
# Reorder the columns (excluding 'language_code' which will be the index)
label_percentages_pd = label_percentages_pd.set_index("language_code")[column_order]
plt.figure(figsize=(15, 10))
sns.heatmap(
label_percentages_pd,
annot=True,
fmt=".1f", # Keep one decimal place
cmap="YlOrRd",
cbar_kws={"label": "Percentage (%)"},
square=False, # Changed from True to allow rectangular cells
)
plt.xticks(rotation=45, ha="right")
plt.yticks(rotation=0)
# Add more padding
plt.title("Distribution of Labels by Language (%)", pad=5)
plt.tight_layout()
plt.show()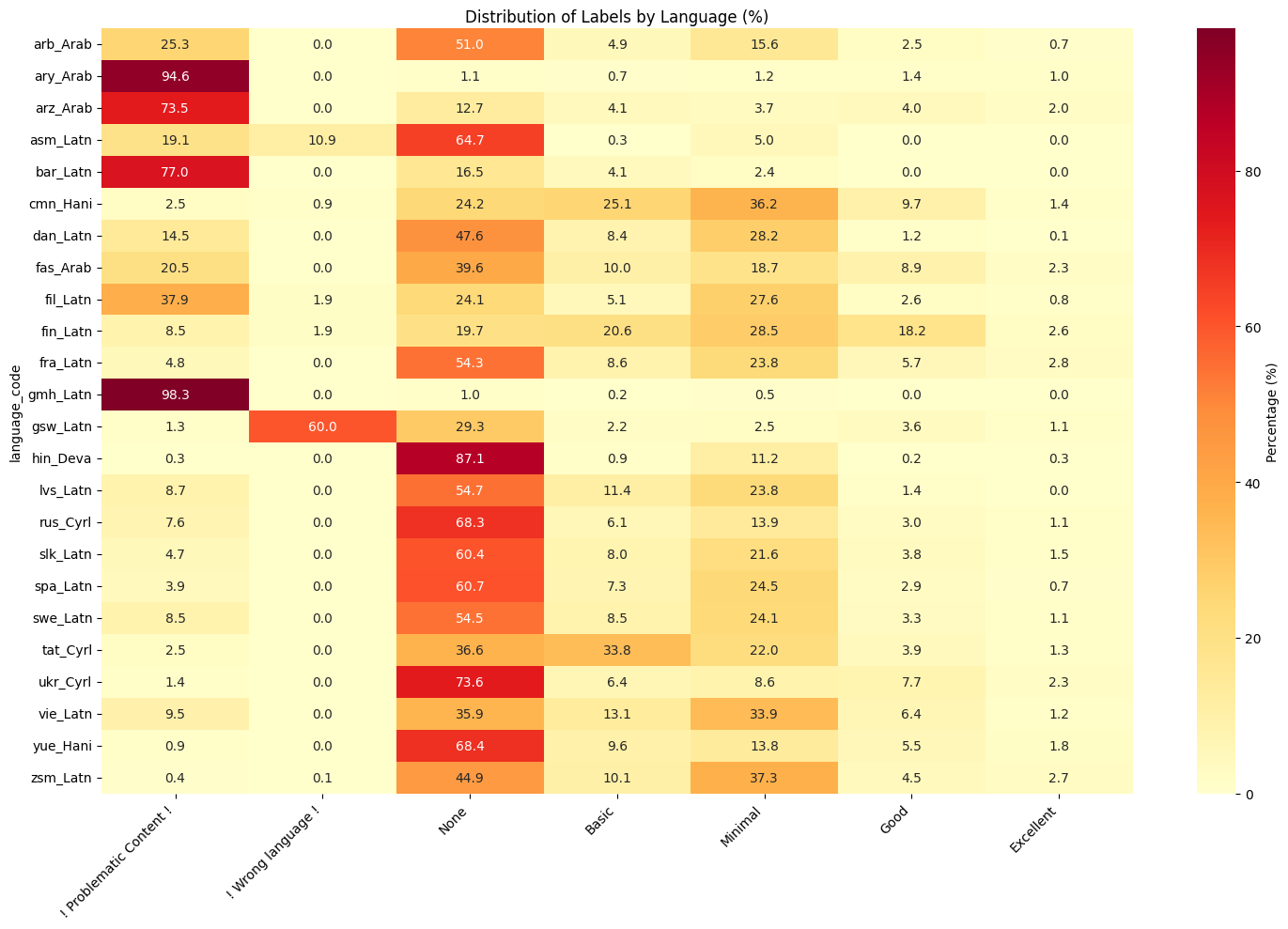
We can also look at the distribution of labels as a bar chart.
Click to show/hide code
import altair as alt
# Convert the wide-format data to long format for Altair
plot_df = label_percentages.unpivot(
index=["language_code"],
on=label_percentages.columns[1:], # All columns except language_code
variable_name="label",
value_name="percentage",
)
# Create the Altair chart
chart = (
alt.Chart(plot_df)
.mark_bar()
.encode(
x="language_code",
y=alt.Y("percentage", stack="zero"),
color="label",
tooltip=["language_code", "label", "percentage"],
)
.properties(
width=1000,
height=500,
title="Label Distribution by Language",
)
.configure_axis(labelAngle=45)
)
chartRefining FineWeb2 for more languages aka next steps
We can see that the distribution of labels varies a fair amount between languages. Some are mostly problematic labels whilst others have a much better distribution of labels. This can also inform what is the best next step for a languages as part of the FineWeb-C project.
Better starting data for annotators aka more filtering of problematic data
FineWeb2 already has a lot of filters to try and identify high quality data, however this is challenging to do across many many languages. This is why the community is so important.
- If a language has a lot of problematic or None labels it makes sense to focus on getting higher quality data filtered for that language.
- In a previous blog post I showed some approaches to how this can be done for a single language. The best approach will depend on the language but developing better heuristics for more languages can be very impactful. This is another area where the community can help!
- Some languages have a lot of data that has been incorrectly identified as the wrong language. This is a problem for the community as it means annotators have to spend a lot of time annotating data that is not useful. For these languages if the community has better heuristics or models for identifying the wrong language we can filter out more data.
Evaluating agreement between annotators
If a language has a good distribution of labels the next step is to try and look at the agreement between annotators. This can help us understand how much we can trust the labels and also help us understand where the labels are ambiguous.
Evaluating LLMs to build training data for a classifier?
For languages where we have fairly good agreement (or at least a subset of good agreement) we can already start to evaluate how well LLMs can do at identifying educational content. Remembering back to the overall goal of this effort, is to reproduce something similar to FineWeb-Edu. This is a subset of the original FineWeb dataset which has been filtered for educational content. This filtering was done by first training a classifier on the original FineWeb-Edu dataset and then using this classifier to filter the original FineWeb dataset. That classifier was training on labels generated by Llama. For some languages it might be possible to take a similar approach. We can do something like:
- Evaluate how well an LLM does in comparison to our annotators. This might require experimenting with different LLMs and prompting approaches. I’m working on a notebook to do this but this is another area where the community can help.
- If the LLM does a good job we can then use it to create enough data to start to train a classifier.
Training educational quality classifiers
Some languages already have quite a lot of data with a fairly good distribution of labels. For these languages we can already see if we have sufficient data to train a classifier. It’s likely for most languages we’d need more data but starting to train a classifier can be a good next step. Again this is another area where the community can help!
As you may have noticed, I’ve been using the word “community” a lot in this post. This is because I think this is a really important part of the FineWeb-C project. We have a Discord channel where we can discuss the project and share ideas. If you’re interested in contributing to the project please join the channel and let’s chat!