Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=947318989803-6bn6qk8qdgf4n4g3pfee6491hc0brc4i.apps.googleusercontent.com&redirect_uri=urn%3aietf%3awg%3aoauth%3a2.0%3aoob&response_type=code&scope=email%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdocs.test%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive.photos.readonly%20https%3a%2f%2fwww.googleapis.com%2fauth%2fpeopleapi.readonly
Enter your authorization code:
··········
Mounted at /content/drive
the motivations for ‘pragmatic hyperparameters optimization’
how to do this using Optuna (with an example applied to the fastai2 library)
Optimizing hyperparameters?
Deep learning models have a range of Hyperparameters. These include the basic building blocks of a model like the number of layers used or the size of embedding layers, and the parameters for the training of models such as learning rate. Changing some of these parameters will improve the performance of a model. There is therefore a potential win from finding the right values for these parameters.
Auto ML vs pragmatic hyperparameters optimization
As a way of framing ‘pragmatic search’, it is useful to contrast it to Auto ML. If you haven’t come across it before:
The term AutoML has traditionally been used to describe automated methods for model selection and/or hyperparameter optimization. - {% fn 1 %}.
In particular what is termed Auto ML often includes a search across model and Hyperparameters but can also refer to ‘Neural Architecture Search’ in which the objective is to piece together a new model type for a specific problem or dataset. An underlying assumption of some of this Auto ML approach is that each problem or dataset requires a unique model architecture.
In contrast a more ‘pragmatic’ approach uses an existing model architectures which have been shown to work across a range of datasets and tasks, and utilise transfer learning and other ‘tricks’ like cyclical learning rates and data augmentation. In a heritage context, it is likely that there are going to be bigger issues with imbalanced classes, noisy labels etc, and focusing on designing a custom architecture is probably going to lead to modest improvements in the performance of the model.
So what remains to be optimized?
In contrast to Auto ML which can involve looking at huge range of potential architectures and parameters we could instead limit our focus to smaller set of things which may have a large impact on the performance of your model.
As an example use case for hyperparameters optimization I’ll use two datasets which contain transcripts of trials from the Old Bailey online and which are classified into various categories (theft, deception, etc). One of the datasets is drawn the decade 1830 the other one 1730.
The approach taken to classifying these trials will be to follow the “Universal Language Model Fine-tuning for Text Classification” approach. {% fn 2 %}.
I won’t give an in depth summary of the approach here but idea is that:
A language model - in this case a LSTM based model - is trained on a Wikipedia text. This provides a “general” language model that learns to “understand” general features of a language, in this case English
this language model is then fine-tuned on a target dataset, in the orginal paper this is IMDB movie reviews.
one this language model has been fine-tuned on the target dataset this fine-tuned language model is used as input for a classifier
The intuition here is that by utilising a pre-trained language model the Wikipedia part, and the fine-tuning part we get the benefits of a massive training set (Wikipedia) whilst also being able to ‘focus’ the language model on a target corpus which will use language differently. This makes a lot of intuitive sense, but a question in this use case is how much to fine-tune the language model on our target datasets. A reasonable assumption might be that since language will be more different in 1730 compared to 1830 we may want to fine tune the language model trained on Wikipedia more on the 1730 dataset.
We could of course test through some trial and error experiments, but this is a question which may benefit from some more systematic searching for appropriate hyperparameters. Before we get into this example in more depth I’ll discuss the library I’m working with for doing this hyperparameter searching.
There are some really nice features in Optuna which I’ll cover in this post as I explore the question of language model fine-tuning, so hopefully even if you don’t care about the specific use case it might still provide a useful overview of Optuna.
In this blog post my examples will use version two of the fastai library but there really isn’t anything that won’t translate to other frameworks. Optuna has integrations for a number of libraries (including version 1 of fastai) but for this blog I won’t use this integration.
A simple optimization example
To show the approach used in Optuna I’ll use a simple image classification example. In this case using a toy example of classifying people vs cats in images taken from 19th Century books.
Optuna has two main concepts to understand: study and trial. A study is the overarching process of optimization based on some objective function. A trial is a single test/execution of the objective function. We’ll return to this in more detail. For now lets look at a simple example.
For our first example we’ll just use Optuna to test whether to use a pre-trained model or not. If the option is True then the ResNet18 model we use will use weights from pre-training on ImageNet, if False the model will start with random weights.
Looking at the high level steps of using Optuna (I’ll go into more detail later). We create an objective function:
Most of this will look familiar if you are have used fastai before. Once we have this we create a study:
study = optuna.create_study(direction='maximize')
and then optimize this study:
study.optimize(objective, n_trials=2)
epoch
train_loss
valid_loss
accuracy
time
0
1.503035
0.710954
0.555556
00:06
[I 2020-06-04 16:58:49,862] Finished trial#0 with value: 0.5555555820465088 with parameters: {'pre_trained': False}. Best is trial#0 with value: 0.5555555820465088.
epoch
train_loss
valid_loss
accuracy
time
0
1.691165
1.218440
0.555556
00:05
[I 2020-06-04 16:58:56,272] Finished trial#1 with value: 0.5555555820465088 with parameters: {'pre_trained': False}. Best is trial#0 with value: 0.5555555820465088.
Once we’ve run some trials we can inspect the study object for the best value we’re optimizing for. In this case this is the accuracy but it will be whatever is returned by our function. We can also see the parameters which led to this value.
study.best_value, study.best_params
(0.5555555820465088, {'pre_trained': False})
This toy example wasn’t particularly useful (it just confirmed we probably want to use a pre-trained model) but going through the steps provides an overview of the main things required by Optuna. Starting with defining a function objective
def objective(trial):
this is the function we want to optimize. We could call it something else but following the convention in the Optuna docs the function we’ll call it objective. This function takes ‘trial’ as an argument.
here we use trial to “suggest” a categorical in this case one of two options (whether pre trained is set to true or false). We do this using trial.suggest_categorical and pass it the potential options (in this case True or False).
trial.suggest_blah defines the paramater “search space” for Optuna. We’ll look at all of the options for this later on. The final step in defining our objective function i.e. the thing we want to optimize:
return acc
This return value is objective value that Optuna will optimize. Because this is just the return value of a function there is a lot of flexibility in what this can be. In this example it is accuracy but it could be training or validation loss, or another training metrics. Later on we’ll look at this in more detail.
Now let’s look at the study part:
study = optuna.create_study(direction='maximize')
This is the most simple way of creating a study. This creates a study object, again, we’ll look at more options as we go along. The one option we pass here is the direction. This refers to to whether Optuna should try to increase the return value of our optimization function or decrease it. This depends on what you a tracking i.e. you’d want to minimize error or validation loss but increase accuracy or F1 score.
Looking at the overview provided in the Optuna docs we have three main building blocks:
Trial: A single call of the objective function
Study: An optimization session, which is a set of trials
Parameter: A variable whose value is to be optimized
This is a crucial point. Particularly if we want to use optimization in a pragmatic way. When we have existing knowledge or evidence about what works well for a particular problem, we should use that rather than asking Optuna to find this out for us. There are some extra tricks to make our search for the best parameters more efficient which will be explored below but for now let’s get back to the example use case.
For the sake of brevity I won’t cover the steps to generate this dataset the instructions for doing so for the 1830s trials can be found here (and can be easily adapted for the 1730s trial).
#hide_input df_1830.head(2)
Unnamed: 0
Unnamed: 0.1
0
file
broad
narrow
text
0
14463.0
t18361128-57a
theft-housebreaking
t18361128-57a.txt
theft
housebreaking
\n\n\n\n\n57. \n\n\n\n\nJOHN BYE\n the younger and \n\n\n\n\nFREDERICK BYE\n were indicted for\n\n feloniously breaking and entering the dwelling-house of \n\n\n\nJohn Bye, on the \n21st of November, at \nSt. Giles-in-the-Fields, and stealing therein 12 apples, value 9d.; 1 box, value 1d.; 24 pence, and 1 twopenny-piece; the goods and monies of \n\n\n\nMary Byrne.\n\n\n\n\n\n\nMARY BYRNE\n. I sell fruit; I live in Titchbourne-court, Holborn. On the 21st of November I went out at one o'clock, and locked my door?I left 2s. worth of penny-pieces in my drawer, and two dozen large apples?I came...
1
19021.0
t18380917-2214
theft-pocketpicking
t18380917-2214.txt
theft
pocketpicking
\n\n\n\n2214. \n\n\n\n\nMARY SMITH\n was indicted\n\n for stealing, on the \n16th of September, 1 purse, value 2d.; 3 half-crowns, and twopence; the goods and monies of \n\n\n\nGeorge Sainsbury, from his person.\n\n\n\n\n\n\nGEORGE SAINSBURY\n. Between twelve and one o'clock, on the 16th of September, I went to sleep in the fields, at Barnsbury-park, Islington, I had three half-crowns, and twopence, in my pocket?I was awoke, and missed my money?I went to the prisoner, and charged her with it?she said she had not got it?I followed her, and saw her drop ray purse down, it had two penny piece...
In the example above trial.suggest_categorical was used to define the potential parameter. Optuna has five kinds of parameters which can be optimized. These all work through the trial.suggest method.
Categorical
This can be used for models, optimizers, and for True/False flags.
The string value provides a key for the parameters which is used to access these parameters later, it’s therefore important to give them a sensible name.
Limiting parameters?
Adding additional trial.suggest to your optimization function increases the search space for Optuna to optimize over so you should avoid adding additional parameters if they are not necessary.
The other way in which the search space can be constrained is to limit the range of the search i.e. for learning rate
if it’s not likely the optimal learning rate will sit outside of this range.
How many parameters you include will also depend on the type of model you are trying to train. In the use case of fine-tuning a language model we will want to limit the options more since language models are generally quite slow to train. If, on the other hand, we were trying to improve an image classification model which only takes minutes to train then searching through a larger parameter space would become more feasible.
Objective function for fine-tuning a language model
The objective function below has two stages; train a language model, use the encoder from this language model for a classifier.
The parameters we’re trying to optimize in this case are:
learning rate for the frozen language model
number of epochs to train only the final layers of the language model
learning rate for the unfrozen language model
number of epochs for training the whole language model
We use lm_learn.no_bar() as a context manager to reduce the amount of logging.
We can give our study a name and also store it in a database. This allows for resuming previous trials later and accessing the history of previous trials. There are various options for database backends outlined in the documentation.
/usr/local/lib/python3.6/dist-packages/optuna/_experimental.py:61: ExperimentalWarning:
Progress bar is experimental (supported from v1.2.0). The interface can change in the future.
[I 2020-06-05 15:12:20,128] Finished trial#0 with value: 0.00440805109922757 with parameters: {'learning_rate_frozen': 0.00014124685078723662, 'head_epochs': 5, 'learning_rate_unfrozen': 0.00010276862511970148, 'lm_body_epochs': 1}. Best is trial#0 with value: 0.00440805109922757.
(#4) [0,4.713407516479492,3.7350399494171143,'00:24']
(#4) [1,3.998744249343872,3.3055806159973145,'00:24']
(#4) [2,3.6486754417419434,3.192685842514038,'00:24']
(#4) [3,3.4996860027313232,3.1756556034088135,'00:24']
(#4) [0,3.4227023124694824,3.163315534591675,'00:27']
(#4) [1,3.3954737186431885,3.140226364135742,'00:27']
(#4) [2,3.3778774738311768,3.125929117202759,'00:27']
(#4) [3,3.357388973236084,3.119621753692627,'00:27']
(#4) [4,3.3542206287384033,3.1186859607696533,'00:27']
epoch
train_loss
valid_loss
accuracy
f1_score
time
0
2.368984
2.121307
0.013333
0.000759
00:11
1
2.335033
2.022853
0.250000
0.368652
00:10
2
2.296630
1.948786
0.313333
0.452365
00:10
[I 2020-06-05 15:16:49,562] Finished trial#1 with value: 0.45236502121696065 with parameters: {'learning_rate_frozen': 0.0060643425219262335, 'head_epochs': 4, 'learning_rate_unfrozen': 2.734844423029637e-05, 'lm_body_epochs': 5}. Best is trial#1 with value: 0.45236502121696065.
(#4) [0,5.3748459815979,4.851675987243652,'00:24']
(#4) [1,5.247058868408203,4.672318935394287,'00:24']
(#4) [2,5.111597061157227,4.559732437133789,'00:24']
(#4) [3,5.026832103729248,4.512131690979004,'00:24']
(#4) [4,4.982809066772461,4.5044732093811035,'00:24']
(#4) [0,4.915407657623291,4.423311233520508,'00:27']
(#4) [1,4.857243061065674,4.394893646240234,'00:27']
epoch
train_loss
valid_loss
accuracy
f1_score
time
0
2.368439
2.036706
0.240000
0.360355
00:10
1
2.359790
2.093103
0.033333
0.045878
00:09
2
2.331945
2.140194
0.016667
0.013589
00:10
[I 2020-06-05 15:20:20,119] Finished trial#2 with value: 0.013588651008106425 with parameters: {'learning_rate_frozen': 0.0001971120155925954, 'head_epochs': 5, 'learning_rate_unfrozen': 1.0649951798153689e-05, 'lm_body_epochs': 2}. Best is trial#1 with value: 0.45236502121696065.
Results
You can see how trials are peforming in the logs with the last part of the log reporting the best trial so far. We can now access the best value and best_params.
As I mentioned at the start I think it’s worth trying to think pragmatically about how to use hyper-parameter optimizations. I already mentioned limiting the number of parameters and limiting the potential options in these parameters. However we can also intervene more directly in how Optuna runs a trial.
Suggesting a learning rate
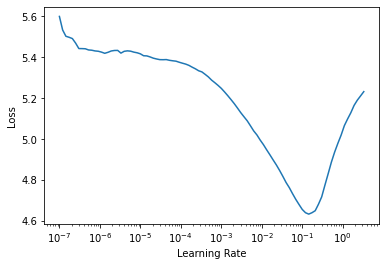
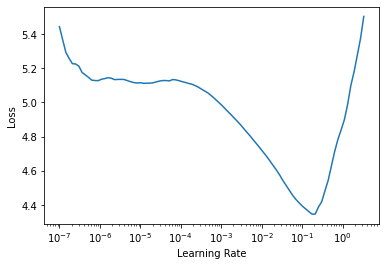
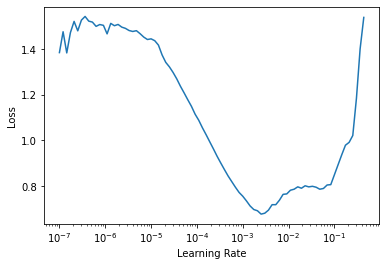
One of the yummiest features in fastai which has also made it into other deep-learning libraries is the learning rate finer lr_find(). As a reminder:
the LR Finder trains the model with exp onentially growing learning rates from start_lr to end_lr for num_it and stops in case of divergence (unless stop_div=False) then plots the losses vs the learning rates with a log scale.
Since the Learning rate finder often gives a good learning rate we should see if we can use this as a starting point for our trials.
Enqueue trial
Using enqueue_trial you can queue up trials with specied paramters. This can be for all of the parameters or just a subset. We can use lr_find to suggest a learning rate for the language model and then que a trial with this learning rate.
/usr/local/lib/python3.6/dist-packages/optuna/_experimental.py:61: ExperimentalWarning:
enqueue_trial is experimental (supported from v1.2.0). The interface can change in the future.
[I 2020-06-05 15:28:58,707] Finished trial#3 with value: 0.6866621960133127 with parameters: {'head_epochs': 4, 'learning_rate_frozen': 0.0003841551576945897, 'learning_rate_unfrozen': 0.033113110810518265, 'lm_body_epochs': 4}. Best is trial#3 with value: 0.6866621960133127.
Using the learning rate from the LR_finder gives us our best trial so far. This is likely to be because learning rate is a particularly important hyper-parameter. The suggested learning rate from lr_find may not always be the best but using either the suggested one or picking one based on the plot as a starting point for the trial may help Optuna to start from sensible starting point while still giving the freedom for optuna to diverge away from this in later trials if helps the objective function.
Pruning trials
The next feature of Optuna which helps make parameter searching more efficient is pruning. Pruning is a process for stopping bad trials early.
For example if we have the following three trials: - Trial 1 - epoch 1: 87% accuracy - Trial 2 - epoch 1: 85% accuracy - Trial 3 - epoch 1: 60% accuracy
probably it’s not worth continuing with trial 3. Pruning trials helps focus computational resources on trials which are likely to improve on previous trials. The likely here is important. It is possible that some trials may be pruned early which actually would have done better in the end. Optuna offers a number of different pruning algorithms, I won’t cover these here but the documentation gives a good overview and includes links to the papers which propose the implemented pruning algorithms.
How to do pruning in Optuna?
Optuna has intergrations with various machine learning libraries. These intergrations can help with the pruning but setting up pruning manually is also pretty straight forward to do.
The two things we need to do is report the value and the stage in the training porcess:
trial.report(metric, step)
then we call:
if trial.should_prune():raise optuna.exceptions.TrialPruned()
Depending on your objective function this will be put in different places. In the example of fine-tuning the language model, because we’re trying to optimize the classification part it, it means the pruning step can only be called quite late in the traing loop. Ideally it would be called earlier but we still save a little bit of time on unpromising trials.
The new objective function with pruning:
def objective(trial): lm_learn = create_lm() lr_frozen = trial.suggest_loguniform("learning_rate_frozen", 1e-4, 1e-1) head_epochs = trial.suggest_int("head_epochs", 1, 5)with lm_learn.no_bar(): lm_learn.fit_one_cycle(head_epochs, lr_max=lr_frozen)# Unfrozen Language model lr_unfreeze = trial.suggest_loguniform("learning_rate_unfrozen", 1e-7, 1e-1) body_epochs = trial.suggest_int("lm_body_epochs", 1, 5) lm_learn.unfreeze()with lm_learn.no_bar(): lm_learn.fit_one_cycle(body_epochs, lr_unfreeze) lm_learn.save_encoder("finetuned")# Classification cl_learn = create_class_learn() cl_learn.load_encoder("finetuned")for step inrange(3): cl_learn.fit(1)# Pruning intermediate_f1 = cl_learn.recorder.values[-1][-1 ] # get f1 score for current step trial.report(intermediate_f1, step) # report f1if trial.should_prune(): # let optuna decide whether to pruneraise optuna.exceptions.TrialPruned() f1 = cl_learn.recorder.values[-1][-1]return f1
We can load the same study as before using the python load_if_exists flag.
Trials can be accssed as part of the study object. Running trials for 30 mins with early pruning results in 20 trials
len(study.trials)
20
We can also see which was the best trial.
study.best_trial.number
2
The number of trials run depends mainly on how long your model takes to train, the size of the paramter search space and your patience. If trials are failing to improve better scores for a long time it’s probably better to actively think about how to improve your approach to the problem (better data, more data, chaning model design etc.) rather than hoping hyperaparmet tuning will fix the problem.
Optuna has a variety of visulizations, I will only briefly show a few of these here.
plot_intermediate_values shows the intermediate values. This can be useful for getting a sense of how trials progress and also help give a sense of whether some trials are being pruned prematurely
plot_parallel_coordinate plots parameters choices in relation to values. It can be hard to read these plots but they can also be helpful for giving a sense of which choices for parameters work best.
/usr/local/lib/python3.6/dist-packages/optuna/_experimental.py:61: ExperimentalWarning:
get_param_importances is experimental (supported from v1.3.0). The interface can change in the future.
/usr/local/lib/python3.6/dist-packages/optuna/_experimental.py:83: ExperimentalWarning:
MeanDecreaseImpurityImportanceEvaluator is experimental (supported from v1.5.0). The interface can change in the future.
/usr/local/lib/python3.6/dist-packages/optuna/_experimental.py:61: ExperimentalWarning:
get_param_importances is experimental (supported from v1.3.0). The interface can change in the future.
/usr/local/lib/python3.6/dist-packages/optuna/_experimental.py:83: ExperimentalWarning:
MeanDecreaseImpurityImportanceEvaluator is experimental (supported from v1.5.0). The interface can change in the future.
These are broadly similar although learning rate frozen/unfrozen are in different places for the 1730 and 1830 trials.
Multi objective
Optuna has experimental support for multi-objective optimization. This might be useful if you don’t want to optimize for only one metrics.
An alternative to using this approach is to report other things you care about during the trial but don’t directly want to optimize for. As an example, you might mostly care about the accuracy of a model but also care a bit about how long it takes to do inference.
One approach is to use a multi-objective trial. An alternative is to instead log inference time as part of the trial and continue to optimize for other metrics. You can then later on balance the accuracy of different trials with the inference time. It may turn out later that a slightly slower inference time can be dealt with by scaling vertically. Not prematurely optimizing for multi-objectives can therefore give you more flexibility. To show this in practice I’ll use an image classification dataset.
Since the time to train the model is more reasonable we can add a more parameters to the search space. In practice this is pretty overkill but is useful as an example of working with the outputs of trials with many parameters.
/usr/local/lib/python3.6/dist-packages/optuna/_experimental.py:61: ExperimentalWarning:
enqueue_trial is experimental (supported from v1.2.0). The interface can change in the future.
/usr/local/lib/python3.6/dist-packages/optuna/_experimental.py:61: ExperimentalWarning:
Progress bar is experimental (supported from v1.2.0). The interface can change in the future.
/usr/local/lib/python3.6/dist-packages/optuna/_experimental.py:61: ExperimentalWarning:
enqueue_trial is experimental (supported from v1.2.0). The interface can change in the future.
/usr/local/lib/python3.6/dist-packages/optuna/_experimental.py:61: ExperimentalWarning:
Progress bar is experimental (supported from v1.2.0). The interface can change in the future.
/usr/local/lib/python3.6/dist-packages/optuna/_experimental.py:61: ExperimentalWarning:
get_param_importances is experimental (supported from v1.3.0). The interface can change in the future.
/usr/local/lib/python3.6/dist-packages/optuna/_experimental.py:83: ExperimentalWarning:
MeanDecreaseImpurityImportanceEvaluator is experimental (supported from v1.5.0). The interface can change in the future.
Learning rate is by far the most important learning rate, again this suggests that using learning rate finder makes a lot of sense as a starting point.
Working with Optuna trial data
There are now ~500 trials which are stored in the study. Each of these trials contains the parameters used, metadata about the trial, the value of the thing being optimized, and importantly for this example the user attribute which stores the validation time. Optuna makes it very easy to export this information to a dataframe.
If we were happy with slightly lower performance we could pick the study with the shortest execution time which is still achieves a f1 above 94%
df94.loc[96]
number 96
value 0.945755
datetime_start 2020-06-07 15:57:20.382634
datetime_complete 2020-06-07 15:57:54.848296
duration 0 days 00:00:34.465662
params_apply_tfms False
params_do_flip NaN
params_epochs 9
params_flip_vert NaN
params_learning_rate 8.47479e-05
params_max_lighting NaN
params_max_rotate NaN
params_max_zoom NaN
params_model densenet121
params_mult NaN
params_unfrozen_epochs 2
params_unfrozen_learning_rate 4.31178e-07
user_attrs_execute_time 0.837618
system_attrs_completed_rung_0 NaN
system_attrs_completed_rung_1 NaN
system_attrs_fixed_params NaN
state COMPLETE
Name: 96, dtype: object
This is a slightly artificial example but hopefully shows the possibility of logging user attributes which can then be accessed easily later without prematurely optimizing for something which may not be important.
Further reading
Hopefully this post has been a helpful overview of Optuna with a somewhat realistic use case. I would recommend reading the Optuna docs which covers things in much more detail.