%pip install polars datasets accelerate evaluate transformers torch huggingface_hub scikit-learn tensorboard wandb --upgrade Hygge Data - Cozy Content Filtering for a finer Scandinavian FineWeb
polars
huggingface
fineweb
datasets
Training lightweight, disposable web scale data curation models for Scandinavian language texts using the FineWeb-c dataset
How and why to curate Web Scale Data
The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset. - FineWeb blog post
Whilst quality is important, the quantity of data we start with is significant. For example the original FineWeb-2 dataset contains 15 trillion tokens (44TB on disk).
The challenge is then: how can we curate data for LLMs in a scalable way? One possible approach is to use LLMs to help with labelling text. Whilst LLMs can do well on this kind of task (especially when using Structured Generation), scaling LLM labeling to web scale is a challenge.
Last year, FineWeb-Edu showed that filtering data for educational quality could yield improvements for LLMs trained on this filtered data. The approach they took was to first use an LLM to label a subset of data and then use a fine-tuned a much smaller BERT-based model to filter the data.
The publication of ModernBert has shown that there is still a lot of excitement around the use of smaller encoder-based models for labelling tasks, indeed one of the examples they cite in their blog post is the cost of creating FineWeb-Edu if they had used a decoder-only model.
An interesting example is FineWeb-Edu, where model-based quality filtering had to be performed over 15 trillion tokens. The FineWeb-Edu team chose to generate annotations with a decoder-only model, Llama-3-70b-Instruct, and perform the bulk of the filtering with a fine-tuned BERT-based model. This filtering took 6,000 H100 hours, which, at HuggingFace Inference Endpoints’ pricing of $10/hour, comes to a total of $60,000. On the other hand, feeding 15 trillion tokens to popular decoder-only models, even with the lowest-cost option of using Google’s Gemini Flash and its low inference cost of $0.075/million tokens, would cost over one million dollars! ModernBert blog post
The ideal approach then seems to be something like:
- Use an LLM to label a subset of data and use these labels to train a smaller model
- Use a smaller model to make prediction on a large dataset and use these predictions to filter the data
- Profit!
While this may work well for English data, many papers have shown that the performance of LLMs for these kinds of tasks can be much worse than for English.
This is where the FineWeb-c dataset comes in.
The FineWeb-C dataset
FineWeb-C is a community-driven initiative to help create high-quality datasets for training LLMs in multiple languages. Rather than relying solely on LLM-based labeling (which may perform poorly in non-English languages), the FineWeb-C project is based on the Hugging Face community submitting annotations for the educational quality of texts in different languages. The project has seen significant growth, achieving:
- 46,457 total annotations
- Coverage of 114 different languages
- Contributions from 408 annotators
You can contribute yourself using your Hugging Face account here: https://huggingface.co/spaces/data-is-better-together/fineweb-c
The project has already released numbers versions of the dataset currently covering 17 18 languages that reached the 1,000 annotations threshold (this blog post is getting out of date even as I write this thanks to the speed of the community!). This community-driven approach helps ensure that data quality assessment isn’t limited by the capabilities of existing LLMs, particularly for lower-resource languages.
In a previous blog post I discussed how you could use Polars to filter out problematic content from the FineWeb-c dataset. This relied on rules and other heuristics. Whilst this can make sense if you already have good rules. I also a look at the current annotated dataset in this post. This post showed that for some languages we may already have a sufficiently diverse dataset to train a model to label the data.
In this post we’ll see if we can already start using the FineWeb-c dataset to train a model to help curate the FineWeb-2 dataset.
Training a classifier to help curate the FineWeb-2 dataset
The long term goal of FineWeb-C is to create a dataset that can help reproduce FineWeb-Edu for many languages. This basically means we need some data for training a model(s) to label the educational quality of text data. Let’s look at the data the community has created so far to see what we can already do with the data.
First we install the necessary libraries.
import numpy as np
import polars as pl
from scipy.special import softmax
from sklearn.metrics import (
precision_score,
recall_score,
f1_score,
roc_auc_score,
average_precision_score,
confusion_matrix,
precision_recall_curve
)
from sklearn.model_selection import train_test_split
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
TrainingArguments,
Trainer,
EarlyStoppingCallback
)
from datasets import Dataset, DatasetDict
from huggingface_hub import list_repo_filesUnderstand the data
We’ll load the dataset from the Hugging Face Hub using Polars which supports loading data from the Hub.
In this case, we’ll load the “default” config which contains all the languages that have reached the 1,000 annotations threshold.
df = pl.read_parquet("hf://datasets/data-is-better-together/fineweb-c/data/*.parquet")
df = df.lazy()df.select("language_code").unique().collect().to_series().to_list()['lvs_Latn',
'arb_Arab',
'asm_Latn',
'swe_Latn',
'dan_Latn',
'vie_Latn',
'gmh_Latn',
'bar_Latn',
'tat_Cyrl',
'fas_Arab',
'cmn_Hani',
'slk_Latn',
'ukr_Cyrl',
'fin_Latn',
'arz_Arab',
'fra_Latn',
'rus_Cyrl',
'ary_Arab',
'hin_Deva',
'fil_Latn']Can we train a model to work with a subset of languages?
So far we have 18 languages in the dataset. Currently over a 100 languages have some level of annotation so eventually we hope the community will create a dataset for ma ne model per language.
Claude gave me the following visual for languages groups in this dataset (which isn’t super accurate but gives a rough idea of the language families represented in the dataset).

We can see a few possible language groups that it could make sense to train a model on. One potential group is the Germanic languages. Let’s look at the data for these languages.
Note
I focused on Germanic languages to start with as if I squint I can get a rough understanding of the language. I would be very excited to see the community begin to explore all of the languages in the dataset.
germanic_languages = ["gmh_Latn", "dan_Latn", "swe_Latn", "bar_Latn", "lvs_Latn"]What do we want to label?
While the overarching goal of the FineWeb-C project is to create a dataset for training models to label the educational quality of text, in order to effectively train this kind of model we need a reasonable distribution of labels.
Problematic content?
The annotation interface for FineWeb-c looks something like this (using Scots as an example).
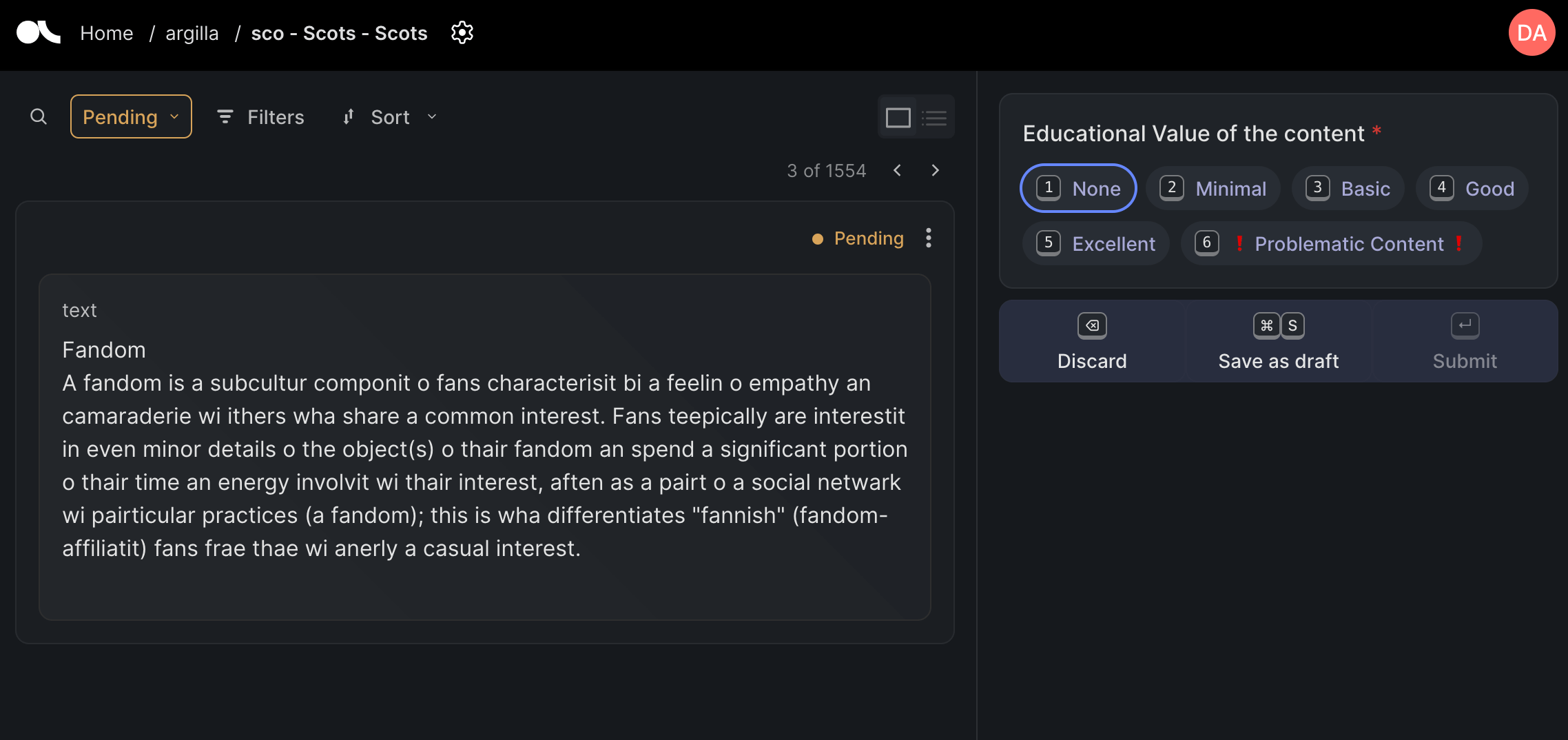
For this example, the annotator could mostly focus on how educational the text is. However, this is the web we’re annotating so we will sometimes come across “problematic” content. This content is usually content in the wrong language i.e. the language predicted during the FineWeb-2 extraction process is incorrect (this happens quite a lot for some languages and much less for others) or the content is garbled in some way. An example of this kind of content is shown below.
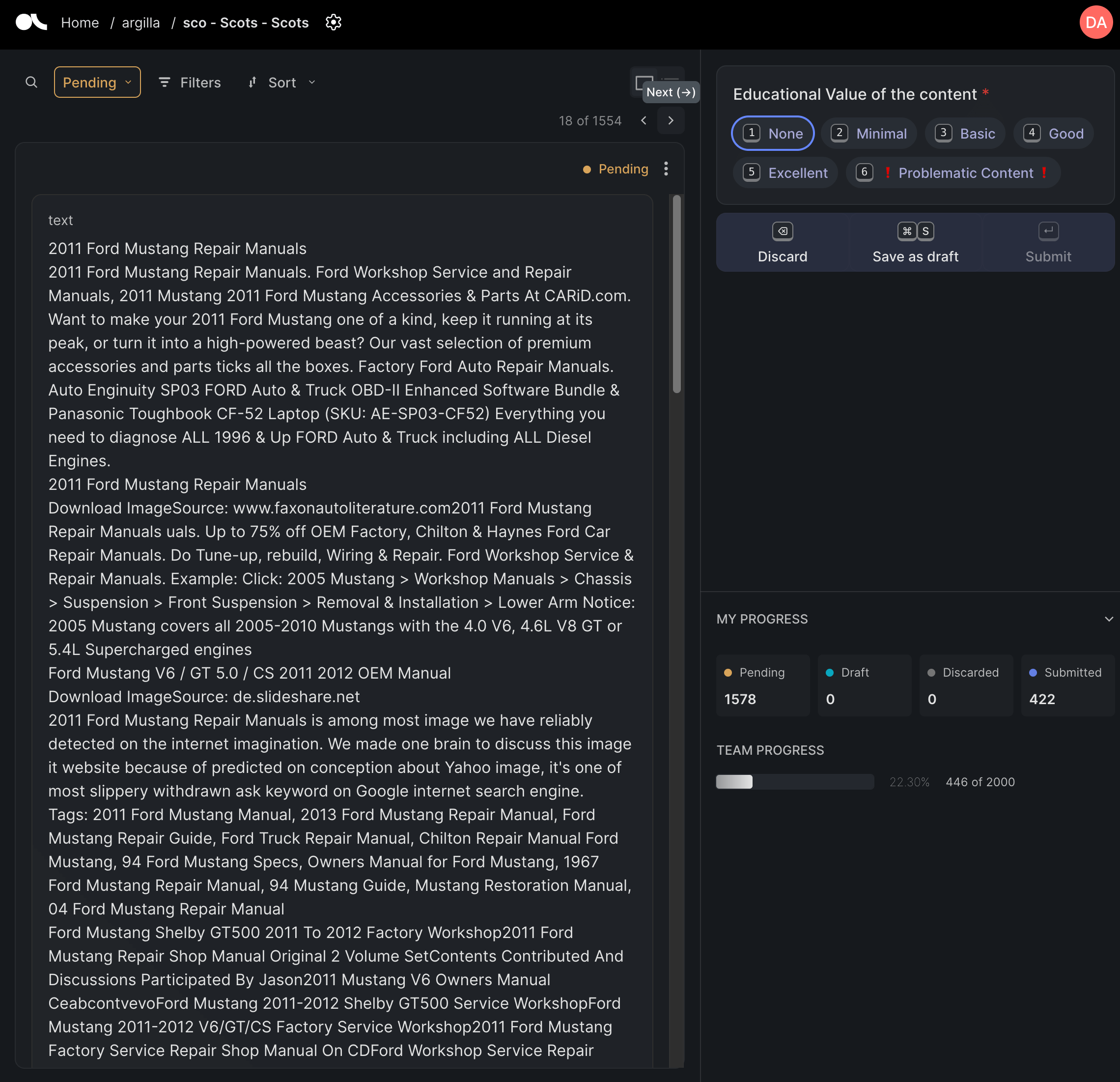
We can see that the content is in the wrong language (English) the text is also somewhat garbled
Note
Why aren’t these just labeled as None i.e. no educational value? Annotating data always comes with some ambiguity. In this case, we added a problematic label to try and make it easier for the community to flag content that was incorrect in some other way. We could have added a whole separate label for this and for the different possible types of issue but this adds extra cognitive load for the annotator. We can also deal with possible overlap in usage of these labels in other ways.
Before we dive into training an educational quality classifier, let’s look at the data for the Germanic languages and see how often this problematic content is present. We’re using Polars in Lazy mode but it’s not really necessary for the size of the dataset at the moment. In the future the dataset might become large enough that this can be more important.
df_germanic = df.filter(pl.col("language_code").is_in(germanic_languages))Let’s start by seeing the percentage of problematic content for each language in the “germanic” group.
(
df_germanic.group_by("language_code")
.agg(
[
(
pl.col("problematic_content_label_present").sum()
/ pl.col("problematic_content_label_present").count()
* 100
).alias("problematic_percentage")
]
)
.sort("problematic_percentage", descending=True)
).collect()
shape: (5, 2)
| language_code | problematic_percentage |
|---|---|
| str | f64 |
| "gmh_Latn" | 98.3 |
| "bar_Latn" | 77.0 |
| "dan_Latn" | 19.4 |
| "swe_Latn" | 8.8 |
| "lvs_Latn" | 8.7 |
We can see that for some of the languages in this group the percentage of problematic content is very high. In particular Bavarian and Middle High German have a very high percentage of problematic content. The other languages have a much lower percentage of problematic content.
Making the lives of annotators easier and getting more educational?
While we could jump to training a model to label the educational quality of the text, we may wan to start in a more modest way. In my previous blog post I generated this plot showing the distribution of educational value for languages in the dataset.

While some languages have a fairly good distribution of educational value labels, most have very few examples of “Excellent” educational quality content. This is not surprising – the majority of the web is not educational…
For languages with very few examples of any educational content training a classifier to label the educational quality of the text is not going to work well. For these languages we probably want to first focus on being able to remove problematic content so we reduce the amount of “noise” annotators need to spend time on and then can instead focus on labelling content that is more likely to be educational.
For this we’ll train a model to label problematic content. We’ll start with the Scandinavian languages since we have Danish and Swedish datasets completed and these languages are somewhat similar (don’t come at me Danish and Swedish speaker – I’ve watched the Bridge!)
Note
This is not the only approach we could take but it could be a good starting point. Even if we don’t end up with sufficient data to train a model to label the educational quality of the text, we can still use this model to remove problematic content and improve the quality of the data we have for some languages.
Training out hygge model
Let’s start by loading the data for the Scandinavian languages.
scandinavian_languages = ["swe_Latn", "dan_Latn"]df_scandinavian = df.filter(pl.col("language_code").is_in(scandinavian_languages))We can see that we have 1,000 annotations for each language.
df_scandinavian.collect().shape(2000, 8)Now let’s get a better understanding of the data. Swedish and Danish both have multiple annotations for many of the texts. This means multiple annotators have looked at the same text and given their assessment of the educational value. Let’s take a look at some examples where the annotators disagree i.e. gave different labels.
df_scandinavian.filter(
pl.col("educational_value_labels").list.unique().list.len() > 1
).collect()
shape: (524, 8)
| id | text | educational_value_labels | annotator_ids | problematic_content_label_present | problematic_content_label_agreement | language_names | language_code |
|---|---|---|---|---|---|---|---|
| str | str | list[str] | list[str] | bool | f64 | str | str |
| "d0347a16-14a6-40c7-a1b8-3d27b9… | "Virkelige får de vil ha sjæl o… | ["❗ Problematic Content ❗", "None", "❗ Problematic Content ❗"] | ["a0585a5c-b72f-4c3a-a2a3-17e8e0b4ea4f", "85ac8d54-89c5-4473-95c4-797366f03cd0", "e9f72b47-2af5-4b06-90f2-7163de147a1d"] | true | 0.666667 | "dan_Latn" | "dan_Latn" |
| "ec7699c9-78e2-48ef-945e-9b0a71… | "Alle drømmer om den store gevi… | ["None", "Minimal", "Basic"] | ["a0585a5c-b72f-4c3a-a2a3-17e8e0b4ea4f", "85ac8d54-89c5-4473-95c4-797366f03cd0", "9987848b-debb-4ed3-a97b-14eb9b3c4322"] | false | 1.0 | "dan_Latn" | "dan_Latn" |
| "49de8369-2b33-47d2-a877-2fe32b… | "Der er en elektrisk forbindels… | ["Basic", "None", "None"] | ["a0585a5c-b72f-4c3a-a2a3-17e8e0b4ea4f", "b98b0144-391d-4e70-bae0-743ce94e6314", "85ac8d54-89c5-4473-95c4-797366f03cd0"] | false | 1.0 | "dan_Latn" | "dan_Latn" |
| "b20402d1-8250-410c-b177-966b8b… | "Online shopping råd - Levering… | ["Basic", "Minimal"] | ["a0585a5c-b72f-4c3a-a2a3-17e8e0b4ea4f", "85ac8d54-89c5-4473-95c4-797366f03cd0"] | false | 1.0 | "dan_Latn" | "dan_Latn" |
| "dc34ee93-74e2-48ba-9b5c-9d4dfb… | "Morgenmad er det vigtigste mål… | ["Basic", "Basic", "None"] | ["a0585a5c-b72f-4c3a-a2a3-17e8e0b4ea4f", "85ac8d54-89c5-4473-95c4-797366f03cd0", "4e0a264e-6445-495f-ae54-8e0755b8ebd0"] | false | 1.0 | "dan_Latn" | "dan_Latn" |
| … | … | … | … | … | … | … | … |
| "aee9b105-18c3-455d-b07c-545eb2… | "Dronning Victoria afskyede sin… | ["Minimal", "None", "❗ Problematic Content ❗"] | ["a0585a5c-b72f-4c3a-a2a3-17e8e0b4ea4f", "9987848b-debb-4ed3-a97b-14eb9b3c4322", "85ac8d54-89c5-4473-95c4-797366f03cd0"] | true | 0.333333 | "dan_Latn" | "dan_Latn" |
| "42abb527-d3b8-4b23-b88a-d3df06… | "Smarte Opbevaringsløsninger ti… | ["Minimal", "None"] | ["a0585a5c-b72f-4c3a-a2a3-17e8e0b4ea4f", "85ac8d54-89c5-4473-95c4-797366f03cd0"] | false | 1.0 | "dan_Latn" | "dan_Latn" |
| "7076624a-7b72-4534-bfdc-a4b6fc… | "Power Automate er under udbred… | ["Basic", "None", "Minimal"] | ["a0585a5c-b72f-4c3a-a2a3-17e8e0b4ea4f", "740270b9-61bf-4d85-a495-9e37270f7257", "82197ecd-6d0b-400a-834a-703da28164ae"] | false | 1.0 | "dan_Latn" | "dan_Latn" |
| "a97595d9-61b4-4ae7-953c-654a85… | "Kl. 17.30 - 19.30 Home Concert… | ["None", "Minimal", "None"] | ["a0585a5c-b72f-4c3a-a2a3-17e8e0b4ea4f", "9987848b-debb-4ed3-a97b-14eb9b3c4322", "85ac8d54-89c5-4473-95c4-797366f03cd0"] | false | 1.0 | "dan_Latn" | "dan_Latn" |
| "d3c4b487-6976-45bf-9a81-2c8208… | "J. S. RASCH VIN & SPIRITUS J. … | ["Basic", "Minimal", "None"] | ["a0585a5c-b72f-4c3a-a2a3-17e8e0b4ea4f", "82197ecd-6d0b-400a-834a-703da28164ae", "85ac8d54-89c5-4473-95c4-797366f03cd0"] | false | 1.0 | "dan_Latn" | "dan_Latn" |
Even with a quick eyeball we can see that often “problematic” or None are used to label the same text. Similarly “minimal” or “none” are used to label the same text. This isn’t so surprising since the educational quality is fairly subjective. The main thing we probably don’t want too much of is content with very extreme labels i.e None vs Excellent. We can take a closer look at the combinations of labels that are used. Let’s take a look at the unique combinations of non agreeing labels.
Code
(
df_scandinavian.filter(
pl.col("educational_value_labels").list.unique().list.len() > 1
)
.select(
pl.col("educational_value_labels").list.sort().alias("educational_value_labels")
)
.unique()
).collect()
shape: (37, 1)
| educational_value_labels |
|---|
| list[str] |
| ["Basic", "Good", "Minimal"] |
| ["Good", "Minimal"] |
| ["Basic", "Good"] |
| ["Minimal", "Minimal", "❗ Problematic Content ❗"] |
| ["Basic", "None", "❗ Problematic Content ❗"] |
| … |
| ["Good", "None", "None"] |
| ["None", "❗ Problematic Content ❗", "❗ Problematic Content ❗"] |
| ["Good", "Good", "Minimal"] |
| ["Basic", "Minimal", "❗ Problematic Content ❗"] |
| ["Basic", "Basic", "Good"] |
From a quick eyeball we don’t seem to have disagreement that is too extreme. Let’s get a better understanding of the co-occurrence of labels when annotators disagree.
Code
combinations = (
(
df_scandinavian.filter(
pl.col("educational_value_labels").list.unique().list.len() > 1
)
.select(
pl.col("educational_value_labels")
.list.unique()
.list.sort()
.alias("educational_value_labels")
)
.collect()
)
.to_series()
.to_list()
)
combinations[:10][['None', '❗ Problematic Content ❗'],
['Basic', 'Minimal', 'None'],
['Basic', 'None'],
['Basic', 'Minimal'],
['Basic', 'None'],
['Basic', 'None'],
['Basic', 'Minimal', 'None'],
['None', '❗ Problematic Content ❗'],
['None', '❗ Problematic Content ❗'],
['Minimal', 'None']]We can plot this using some code Claude gave me.
Code
import pandas as pd
import numpy as np
# First, let's get all unique labels that appear
all_labels = set()
for combo in combinations: # combinations is your list of lists
all_labels.update(combo)
all_labels = sorted(list(all_labels))
# Create a co-occurrence matrix
cooc_matrix = pd.DataFrame(0, index=all_labels, columns=all_labels)
# Fill the matrix
for combo in combinations:
for label1 in combo:
for label2 in combo:
if label1 != label2:
cooc_matrix.loc[label1, label2] += 1
# Convert to percentage of times labels co-occur
total_occurrences = cooc_matrix.sum().sum()
cooc_matrix_pct = cooc_matrix / total_occurrences * 100
# Print most common co-occurrences
pairs = []
for i in range(len(all_labels)):
for j in range(i + 1, len(all_labels)):
label1, label2 = all_labels[i], all_labels[j]
count = cooc_matrix.loc[label1, label2]
if count > 0:
pairs.append((label1, label2, count))
# Sort by count
pairs.sort(key=lambda x: x[2], reverse=True)
# Print top co-occurrences
print("Most common label combinations:")
for label1, label2, count in pairs[:10]:
print(f"{label1} + {label2}: {count} occurrences")Most common label combinations:
Minimal + None: 305 occurrences
Basic + Minimal: 96 occurrences
None + ❗ Problematic Content ❗: 84 occurrences
Basic + None: 69 occurrences
Good + Minimal: 24 occurrences
Minimal + ❗ Problematic Content ❗: 23 occurrences
Good + None: 12 occurrences
Basic + Good: 11 occurrences
Basic + ❗ Problematic Content ❗: 7 occurrences
Basic + Excellent: 5 occurrencesWe see here that Minimal and None are the most common labels when annotators disagree. We also see some “problematic” labels with None. In the FineWeb-c dataset the problematic_content_label_present is a boolean column that is True if any of the annotators labeled the text as problematic. We want to check that this wouldn’t capture too many examples where another annotator would rate the text highly. If we train a classifier to remove problematic content is may also remove some examples which would be labelled None or possibly minimal but since we’re mostly seeking to get higher educational quality data this isn’t really a problem.
Preparing the data for training
Let’s remind ourselves of the percentage of problematic content for each language we’re working with.
Code
(
df_scandinavian.group_by("language_code").agg(
[
(
pl.col("problematic_content_label_present").sum()
/ pl.col("problematic_content_label_present").count()
* 100
).alias("problematic_percentage")
]
)
).collect()
shape: (2, 2)
| language_code | problematic_percentage |
|---|---|
| str | f64 |
| "swe_Latn" | 8.8 |
| "dan_Latn" | 19.4 |
Let’s now convert our LazyFrame to a Polars DataFrame so it’s a bit easier to pass to other libraries.
df_scandinavian = df_scandinavian.collect()Train / test split
Creating a good train/test split is important for making sure we train a model that generalizes well. We’ll use a stratified split to ensure that the train and test set have a similar distribution of labels. Since we’re working with two language we probably want to stratify on language too.
Code
# Create stratification column
df_scandinavian = df_scandinavian.with_columns(
strat_col=pl.col("language_code")
+ "_"
+ pl.col("problematic_content_label_present").cast(pl.Utf8)
)
# Convert to numpy for sklearn
X = df_scandinavian.select(["id", "text"]).to_numpy() # Including id for tracking
y = df_scandinavian.select("problematic_content_label_present").to_numpy()
strat = df_scandinavian.select("strat_col").to_numpy()
# Create stratified split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=strat, random_state=42
)
# Convert back to Polars DataFrames with all relevant columns
train_indices = set(X_train[:, 0]) # Assuming first column is id
test_indices = set(X_test[:, 0])
train_df = df_scandinavian.filter(pl.col("id").is_in(train_indices))
test_df = df_scandinavian.filter(pl.col("id").is_in(test_indices))Let’s take a look at the distribution of labels in the train and test set by language and label (problematic or not).
Code
print("\nTrain Set:")
# Problematic content percentage by language
print("Label distribution within each language:")
print(
(
train_df.group_by("language_code")
.agg(
[
(
pl.col("problematic_content_label_present").sum()
/ pl.col("problematic_content_label_present").count()
* 100
).alias("problematic_percentage"),
pl.col("problematic_content_label_present")
.count()
.alias("total_count"),
]
)
.sort("language_code")
.with_columns(pl.col("problematic_percentage").round(2))
)
)
# Language distribution
print("\nLanguage distribution in train set:")
print(
(
train_df.group_by("language_code")
.agg(
(pl.len() / train_df.height * 100).alias("percentage_of_split"),
pl.len().alias("count"),
)
.sort("language_code")
.with_columns(pl.col("percentage_of_split").round(2))
)
)
print("\nTest Set:")
# Problematic content percentage by language
print("Label distribution within each language:")
print(
(
test_df.group_by("language_code")
.agg(
[
(
pl.col("problematic_content_label_present").sum()
/ pl.col("problematic_content_label_present").count()
* 100
).alias("problematic_percentage"),
pl.col("problematic_content_label_present")
.count()
.alias("total_count"),
]
)
.sort("language_code")
.with_columns(pl.col("problematic_percentage").round(2))
)
)
# Language distribution
print("\nLanguage distribution in test set:")
print(
(
test_df.group_by("language_code")
.agg(
(pl.len() / test_df.height * 100).alias("percentage_of_split"),
pl.len().alias("count"),
)
.sort("language_code")
.with_columns(pl.col("percentage_of_split").round(2))
)
)
Train Set:
Label distribution within each language:
shape: (2, 3)
┌───────────────┬────────────────────────┬─────────────┐
│ language_code ┆ problematic_percentage ┆ total_count │
│ --- ┆ --- ┆ --- │
│ str ┆ f64 ┆ u32 │
╞═══════════════╪════════════════════════╪═════════════╡
│ dan_Latn ┆ 19.38 ┆ 800 │
│ swe_Latn ┆ 8.75 ┆ 800 │
└───────────────┴────────────────────────┴─────────────┘
Language distribution in train set:
shape: (2, 3)
┌───────────────┬─────────────────────┬───────┐
│ language_code ┆ percentage_of_split ┆ count │
│ --- ┆ --- ┆ --- │
│ str ┆ f64 ┆ u32 │
╞═══════════════╪═════════════════════╪═══════╡
│ dan_Latn ┆ 50.0 ┆ 800 │
│ swe_Latn ┆ 50.0 ┆ 800 │
└───────────────┴─────────────────────┴───────┘
Test Set:
Label distribution within each language:
shape: (2, 3)
┌───────────────┬────────────────────────┬─────────────┐
│ language_code ┆ problematic_percentage ┆ total_count │
│ --- ┆ --- ┆ --- │
│ str ┆ f64 ┆ u32 │
╞═══════════════╪════════════════════════╪═════════════╡
│ dan_Latn ┆ 19.5 ┆ 200 │
│ swe_Latn ┆ 9.0 ┆ 200 │
└───────────────┴────────────────────────┴─────────────┘
Language distribution in test set:
shape: (2, 3)
┌───────────────┬─────────────────────┬───────┐
│ language_code ┆ percentage_of_split ┆ count │
│ --- ┆ --- ┆ --- │
│ str ┆ f64 ┆ u32 │
╞═══════════════╪═════════════════════╪═══════╡
│ dan_Latn ┆ 50.0 ┆ 200 │
│ swe_Latn ┆ 50.0 ┆ 200 │
└───────────────┴─────────────────────┴───────┘Loading as HuggingFace Dataset
We’ll now load the data as a HuggingFace Dataset. We’ll first convert the problematic_content_label_present column to an integer column.
train_df = train_df.with_columns(
pl.col("problematic_content_label_present").cast(pl.Int32)
)
test_df = test_df.with_columns(
pl.col("problematic_content_label_present").cast(pl.Int32)
)train_ds = Dataset.from_polars(train_df)
test_ds = Dataset.from_polars(test_df)We rename the problematic_content_label_present column to labels to match the expected column name for the Transformers Trainer.
train_ds = train_ds.rename_column("problematic_content_label_present", "labels")
test_ds = test_ds.rename_column("problematic_content_label_present", "labels")Fine tuning a model
We’ll now fine tune a model to predict the problematic_content_label_present column. To do this we’ll want a fill-mask model which supports the languages we’re working with. We can find these models using the HuggingFace Hub using this url:
https://huggingface.co/models?pipeline_tag=fill-mask&language=da,sv&sort=trending We can try out a few options but we’ll start with the FacebookAI/xlm-roberta-base model.
Defining metrics
We’ll define a function to compute the metrics we want to use to evaluate the model. Since we’re working with an imbalanced dataset we’ll want to use a few different metrics. We’re probably going a bit overboard here but since the dataset is small it can be useful to have a few more metrics to look at to understand the model’s performance.
def compute_metrics(pred):
"""
Compute metrics including AUC-ROC for the minority class.
"""
# Get labels
labels = pred.label_ids
# Convert logits to probabilities using softmax
probs = softmax(pred.predictions, axis=1)
# Get probability scores for the minority class (assuming it's label 1)
minority_probs = probs[:, 1]
# Get predicted class (argmax of logits)
preds = np.argmax(pred.predictions, axis=1)
# Calculate standard metrics
precision = precision_score(labels, preds)
recall = recall_score(labels, preds)
f1 = f1_score(labels, preds)
# Calculate additional metrics for imbalanced classification
cm = confusion_matrix(labels, preds)
tn, fp, fn, tp = cm.ravel()
specificity = tn / (tn + fp) # True negative rate
balanced_acc = (recall + specificity) / 2 # Balanced accuracy
auc_roc = roc_auc_score(labels, minority_probs)
avg_precision = average_precision_score(labels, minority_probs) # Area under PR curve
return {
"precision": precision,
"recall": recall,
"f1": f1,
"auc_roc": auc_roc,
"balanced_accuracy": balanced_acc,
"average_precision": avg_precision
}Setting up the training
I find it nice to have a mapping between the labels and the ids so later I don’t need to remember which label is which id.
possible_labels = (
df_scandinavian.select("problematic_content_label_present")
.unique()
.to_series()
.to_list()
)
possible_labels[False, True]label2id = {label: i for i, label in enumerate(possible_labels)}
id2label = {0: "not_problematic", 1: "problematic"}Authenticating with HuggingFace
We’ll need to authenticate with HuggingFace to push the model to the Hub.
from huggingface_hub import loginlogin()Logging with Weights & Biases
We’ll also log the training with Weights & Biases.
import wandbwandb.login()wandb: Logging into wandb.ai. (Learn how to deploy a W&B server locally: https://wandb.me/wandb-server) wandb: You can find your API key in your browser here: https://wandb.ai/authorize wandb: Paste an API key from your profile and hit enter, or press ctrl+c to quit:
········wandb: Appending key for api.wandb.ai to your netrc file: /home/user/.netrc
TrueThe training code is not super interesting or particularly elegant. I just wanted to get something working.
Code
def train_model(
train_ds,
test_ds,
hub_model_id,
pre_trained_model_name="distilbert/distilbert-base-multilingual-cased",
num_epochs=20,
batch_size=128,
label2id=None,
id2label=None,
):
"""
Train and evaluate the model with additional metrics for imbalanced classification.
Args:
train_ds: Training dataset
test_ds: Test dataset
hub_model_id: Model ID for pushing to HuggingFace Hub
pre_trained_model_name: Name of pretrained model to use
num_epochs: Number of training epochs
batch_size: Batch size for training
label2id: Dictionary mapping labels to IDs
id2label: Dictionary mapping IDs to labels
"""
tokenizer = AutoTokenizer.from_pretrained(pre_trained_model_name)
model = AutoModelForSequenceClassification.from_pretrained(
pre_trained_model_name,
num_labels=2, # Binary classification
label2id=label2id,
id2label=id2label,
)
def tokenize_function(examples):
"""
Tokenize the text data with proper padding and truncation.
"""
return tokenizer(
examples["text"], padding=True, truncation=True, max_length=512
)
split_dataset = DatasetDict({"train": train_ds, "test": test_ds})
# Tokenize datasets
tokenized_train = split_dataset["train"].map(tokenize_function, batched=True)
tokenized_val = split_dataset["test"].map(tokenize_function, batched=True)
print(f"Tokenized train dataset: {tokenized_train}")
print(f"Tokenized val dataset: {tokenized_val}")
# Set up training arguments
training_args = TrainingArguments(
output_dir="/data/results",
num_train_epochs=num_epochs,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
learning_rate=2e-5,
weight_decay=0.01,
push_to_hub=True,
eval_strategy="steps",
eval_steps=100,
logging_steps=100,
save_strategy="steps",
load_best_model_at_end=True,
metric_for_best_model="auc_roc", # Using AUC-ROC for model selection
greater_is_better=True,
save_total_limit=20,
hub_model_id=hub_model_id,
fp16=True,
save_safetensors=False,
)
trainer = Trainer(
model=model,
args=training_args,
tokenizer=tokenizer, # Using tokenizer instead of processing_class
train_dataset=tokenized_train,
eval_dataset=tokenized_val,
compute_metrics=compute_metrics,
callbacks=[
EarlyStoppingCallback(
early_stopping_patience=8, early_stopping_threshold=0.001
)
],
)
# Train the model
trainer.train()
# Evaluate the model
eval_results = trainer.evaluate()
return trainer, eval_results
def main(
train_ds,
test_ds,
hub_model_id,
pre_trained_model_name="distilbert/distilbert-base-multilingual-cased",
num_epochs=20,
batch_size=128,
label2id=None,
id2label=None,
):
"""
Main training function that handles model training and evaluation.
Args:
train_ds: Training dataset
test_ds: Test dataset
hub_model_id: Model ID for pushing to HuggingFace Hub
pre_trained_model_name: Name of pretrained model to use
num_epochs: Number of training epochs
batch_size: Batch size for training
label2id: Dictionary mapping labels to IDs
id2label: Dictionary mapping IDs to labels
"""
# Train and evaluate the model
trainer, eval_results = train_model(
train_ds=train_ds,
test_ds=test_ds,
hub_model_id=hub_model_id,
pre_trained_model_name=pre_trained_model_name,
num_epochs=num_epochs,
batch_size=batch_size,
label2id=label2id,
id2label=id2label,
)
# Print evaluation results with all metrics
print("\nEvaluation Results:")
print(f"F1 Score: {eval_results['eval_f1']:.4f}")
print(f"Precision: {eval_results['eval_precision']:.4f}")
print(f"Recall: {eval_results['eval_recall']:.4f}")
print(f"AUC-ROC (minority class): {eval_results['eval_auc_roc']:.4f}")
print(
f"Average Precision (minority class): {eval_results['eval_average_precision']:.4f}"
)
print(f"Balanced Accuracy: {eval_results['eval_balanced_accuracy']:.4f}")
return trainer, eval_resultstrainer, results = main(
train_ds,
test_ds,
hub_model_id="davanstrien/scandi-fine-web-cleaner",
pre_trained_model_name="FacebookAI/xlm-roberta-base",
num_epochs=30,
batch_size=16,
label2id=label2id,
id2label=id2label,
)Some weights of XLMRobertaForSequenceClassification were not initialized from the model checkpoint at FacebookAI/xlm-roberta-base and are newly initialized: ['classifier.dense.bias', 'classifier.dense.weight', 'classifier.out_proj.bias', 'classifier.out_proj.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.Tokenized train dataset: Dataset({
features: ['id', 'text', 'educational_value_labels', 'annotator_ids', 'labels', 'problematic_content_label_agreement', 'language_names', 'language_code', 'strat_col', 'input_ids', 'attention_mask'],
num_rows: 1600
})
Tokenized val dataset: Dataset({
features: ['id', 'text', 'educational_value_labels', 'annotator_ids', 'labels', 'problematic_content_label_agreement', 'language_names', 'language_code', 'strat_col', 'input_ids', 'attention_mask'],
num_rows: 400
})/home/user/miniconda/lib/python3.11/site-packages/transformers/training_args.py:1575: FutureWarning: `evaluation_strategy` is deprecated and will be removed in version 4.46 of 🤗 Transformers. Use `eval_strategy` instead
warnings.warn(
/tmp/ipykernel_77/3658588944.py:156: FutureWarning: `tokenizer` is deprecated and will be removed in version 5.0.0 for `Trainer.__init__`. Use `processing_class` instead.
trainer = Trainer(
[1000/3000 02:00 < 04:01, 8.29 it/s, Epoch 10/30]
| Step | Training Loss | Validation Loss | Precision | Recall | F1 | Specificity | Npv | Auc Roc | Average Precision | True Positives | False Positives | True Negatives | False Negatives | Minority Class Ratio | Predicted Minority Ratio | Best F1 Threshold | Best F1 Score | Default Precision | Default Recall | Default F1 | Balanced Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 0.282200 | 0.233291 | 0.851064 | 0.701754 | 0.769231 | 0.979592 | 0.951841 | 0.912562 | 0.808400 | 40 | 7 | 336 | 17 | 0.142500 | 0.117500 | 0.710879 | 0.769231 | 0.800000 | 0.701754 | 0.747664 | 0.840673 |
| 200 | 0.176000 | 0.255909 | 0.941176 | 0.561404 | 0.703297 | 0.994169 | 0.931694 | 0.932229 | 0.821460 | 32 | 2 | 341 | 25 | 0.142500 | 0.085000 | 0.060919 | 0.766355 | 0.942857 | 0.578947 | 0.717391 | 0.777786 |
| 300 | 0.155400 | 0.284004 | 0.948718 | 0.649123 | 0.770833 | 0.994169 | 0.944598 | 0.904225 | 0.812967 | 37 | 2 | 341 | 20 | 0.142500 | 0.097500 | 0.792384 | 0.778947 | 0.948718 | 0.649123 | 0.770833 | 0.821646 |
| 400 | 0.141300 | 0.293026 | 0.816327 | 0.701754 | 0.754717 | 0.973761 | 0.951567 | 0.930004 | 0.826913 | 40 | 9 | 334 | 17 | 0.142500 | 0.122500 | 0.938463 | 0.778947 | 0.816327 | 0.701754 | 0.754717 | 0.837758 |
| 500 | 0.113500 | 0.284364 | 0.972222 | 0.614035 | 0.752688 | 0.997085 | 0.939560 | 0.927190 | 0.824227 | 35 | 1 | 342 | 22 | 0.142500 | 0.090000 | 0.013480 | 0.784314 | 0.945946 | 0.614035 | 0.744681 | 0.805560 |
| 600 | 0.088200 | 0.365192 | 0.880952 | 0.649123 | 0.747475 | 0.985423 | 0.944134 | 0.923252 | 0.818148 | 37 | 5 | 338 | 20 | 0.142500 | 0.105000 | 0.989013 | 0.760870 | 0.880952 | 0.649123 | 0.747475 | 0.817273 |
| 700 | 0.078500 | 0.360336 | 0.972222 | 0.614035 | 0.752688 | 0.997085 | 0.939560 | 0.923047 | 0.819323 | 35 | 1 | 342 | 22 | 0.142500 | 0.090000 | 0.196286 | 0.770833 | 0.945946 | 0.614035 | 0.744681 | 0.805560 |
| 800 | 0.030700 | 0.381501 | 0.759259 | 0.719298 | 0.738739 | 0.962099 | 0.953757 | 0.918853 | 0.826950 | 41 | 13 | 330 | 16 | 0.142500 | 0.135000 | 0.998579 | 0.787234 | 0.745455 | 0.719298 | 0.732143 | 0.840699 |
| 900 | 0.029300 | 0.486526 | 0.971429 | 0.596491 | 0.739130 | 0.997085 | 0.936986 | 0.912894 | 0.812492 | 34 | 1 | 342 | 23 | 0.142500 | 0.087500 | 0.006314 | 0.770833 | 0.972222 | 0.614035 | 0.752688 | 0.796788 |
| 1000 | 0.015900 | 0.468468 | 1.000000 | 0.649123 | 0.787234 | 1.000000 | 0.944904 | 0.909672 | 0.804402 | 37 | 0 | 343 | 20 | 0.142500 | 0.092500 | 0.644980 | 0.787234 | 1.000000 | 0.649123 | 0.787234 | 0.824561 |
Could not locate the best model at /data/results/checkpoint-200/pytorch_model.bin, if you are running a distributed training on multiple nodes, you should activate `--save_on_each_node`.
Evaluation Results:
F1 Score: 0.7872
Precision: 1.0000
Recall: 0.6491
AUC-ROC (minority class): 0.9097
Average Precision (minority class): 0.8044!pip install matplotlibhuggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)Requirement already satisfied: matplotlib in /home/user/miniconda/lib/python3.11/site-packages (3.10.0)
Requirement already satisfied: contourpy>=1.0.1 in /home/user/miniconda/lib/python3.11/site-packages (from matplotlib) (1.3.1)
Requirement already satisfied: cycler>=0.10 in /home/user/miniconda/lib/python3.11/site-packages (from matplotlib) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /home/user/miniconda/lib/python3.11/site-packages (from matplotlib) (4.55.3)
Requirement already satisfied: kiwisolver>=1.3.1 in /home/user/miniconda/lib/python3.11/site-packages (from matplotlib) (1.4.8)
Requirement already satisfied: numpy>=1.23 in /home/user/miniconda/lib/python3.11/site-packages (from matplotlib) (2.2.1)
Requirement already satisfied: packaging>=20.0 in /home/user/miniconda/lib/python3.11/site-packages (from matplotlib) (24.1)
Requirement already satisfied: pillow>=8 in /home/user/miniconda/lib/python3.11/site-packages (from matplotlib) (11.1.0)
Requirement already satisfied: pyparsing>=2.3.1 in /home/user/miniconda/lib/python3.11/site-packages (from matplotlib) (3.2.1)
Requirement already satisfied: python-dateutil>=2.7 in /home/user/miniconda/lib/python3.11/site-packages (from matplotlib) (2.9.0.post0)
Requirement already satisfied: six>=1.5 in /home/user/miniconda/lib/python3.11/site-packages (from python-dateutil>=2.7->matplotlib) (1.16.0)def analyze_thresholds(trainer, min_precision=0.9, min_threshold=0.5, fig_size=(15, 5)):
"""
Analyze model performance across different thresholds using the evaluation dataset.
Finds the lowest threshold that maintains the minimum precision requirement while
staying above a minimum threshold floor.
Args:
trainer: HuggingFace Trainer instance
min_precision: Minimum precision requirement (default: 0.9)
min_threshold: Minimum allowed threshold for binary classification (default: 0.5)
fig_size: Figure size for plots (default: (15, 5))
Returns:
dict: Dictionary containing optimal threshold metrics and probability statistics
"""
import numpy as np
from scipy.special import softmax
from sklearn.metrics import (
precision_score,
recall_score,
f1_score,
precision_recall_curve,
)
import matplotlib.pyplot as plt
def calculate_metrics_at_threshold(probs, true_labels, threshold):
"""Helper function to calculate metrics at a given threshold"""
preds = (probs >= threshold).astype(int)
prec = precision_score(true_labels, preds, zero_division=0)
rec = recall_score(true_labels, preds, zero_division=0)
f1 = 2 * (prec * rec) / (prec + rec) if (prec + rec) > 0 else 0
return prec, rec, f1
# Get predictions
predictions = trainer.predict(trainer.eval_dataset)
probs = softmax(predictions.predictions, axis=1)
minority_probs = probs[:, 1] # Probabilities for positive class
true_labels = predictions.label_ids
# Calculate precision-recall curve
precisions, recalls, thresholds = precision_recall_curve(
true_labels, minority_probs
)
# Find optimal threshold meeting both minimum precision and threshold requirements
valid_indices = np.where(
(precisions[:-1] >= min_precision) & (thresholds >= min_threshold)
)[0]
if len(valid_indices) > 0:
# Take lowest threshold that meets both criteria
optimal_idx = valid_indices[0]
optimal_threshold = thresholds[optimal_idx]
optimal_precision = precisions[optimal_idx]
optimal_recall = recalls[optimal_idx]
else:
# If no threshold meets both criteria, find best precision among valid thresholds
valid_thresholds_idx = np.where(thresholds >= min_threshold)[0]
if len(valid_thresholds_idx) > 0:
optimal_idx = valid_thresholds_idx[
np.argmax(precisions[valid_thresholds_idx])
]
optimal_threshold = thresholds[optimal_idx]
optimal_precision = precisions[optimal_idx]
optimal_recall = recalls[optimal_idx]
else:
# Fallback to minimum threshold if no valid thresholds found
optimal_threshold = min_threshold
optimal_preds = (minority_probs >= min_threshold).astype(int)
optimal_precision = precision_score(
true_labels, optimal_preds, zero_division=0
)
optimal_recall = recall_score(true_labels, optimal_preds, zero_division=0)
# Create plots
plt.figure(figsize=fig_size)
# Plot 1: Precision-Recall curve
plt.subplot(1, 2, 1)
plt.plot(recalls, precisions, label="Precision-Recall Curve")
plt.scatter(
[optimal_recall],
[optimal_precision],
color="red",
label=f"Threshold={optimal_threshold:.2f}\nPrecision={optimal_precision:.2f}\nRecall={optimal_recall:.2f}",
)
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title("Precision-Recall Curve")
plt.grid(True)
plt.legend()
# Plot 2: Metrics vs Threshold
max_prob = np.max(minority_probs)
min_prob = np.min(minority_probs)
# Create threshold range with denser sampling near optimal point
margin = 0.1
threshold_range = np.unique(
np.concatenate(
[
np.linspace(min_threshold, optimal_threshold - margin, 40),
np.linspace(optimal_threshold - margin, optimal_threshold + margin, 20),
np.linspace(optimal_threshold + margin, max_prob, 40),
]
)
)
threshold_range = np.clip(threshold_range, min_threshold, max_prob)
# Calculate metrics for each threshold
metrics = [
calculate_metrics_at_threshold(minority_probs, true_labels, t)
for t in threshold_range
]
precisions_plot, recalls_plot, f1_scores = zip(*metrics)
plt.subplot(1, 2, 2)
plt.plot(threshold_range, precisions_plot, label="Precision")
plt.plot(threshold_range, recalls_plot, label="Recall")
plt.plot(threshold_range, f1_scores, label="F1", linestyle="--")
plt.axvline(
x=optimal_threshold,
color="red",
linestyle="--",
label=f"Optimal Threshold={optimal_threshold:.2f}",
)
plt.axvline(
x=min_threshold,
color="gray",
linestyle=":",
label=f"Min Threshold={min_threshold:.2f}",
)
plt.xlabel("Threshold")
plt.ylabel("Score")
plt.title("Metrics vs Threshold")
plt.grid(True)
plt.legend()
plt.tight_layout()
plt.show()
# Calculate final metrics and probability statistics
optimal_preds = (minority_probs >= optimal_threshold).astype(int)
f1 = f1_score(true_labels, optimal_preds)
mean_prob = np.mean(minority_probs)
print(f"\nProbability Distribution:")
print(f"Min probability: {min_prob:.3f}")
print(f"Max probability: {max_prob:.3f}")
print(f"Mean probability: {mean_prob:.3f}")
return {
"optimal_threshold": optimal_threshold,
"optimal_precision": optimal_precision,
"optimal_recall": optimal_recall,
"optimal_f1": f1,
"min_prob": min_prob,
"max_prob": max_prob,
"mean_prob": mean_prob,
}
# Example usage
results = analyze_thresholds(
trainer,
min_precision=0.9,
min_threshold=0.5, # Enforce minimum threshold of 0.5
)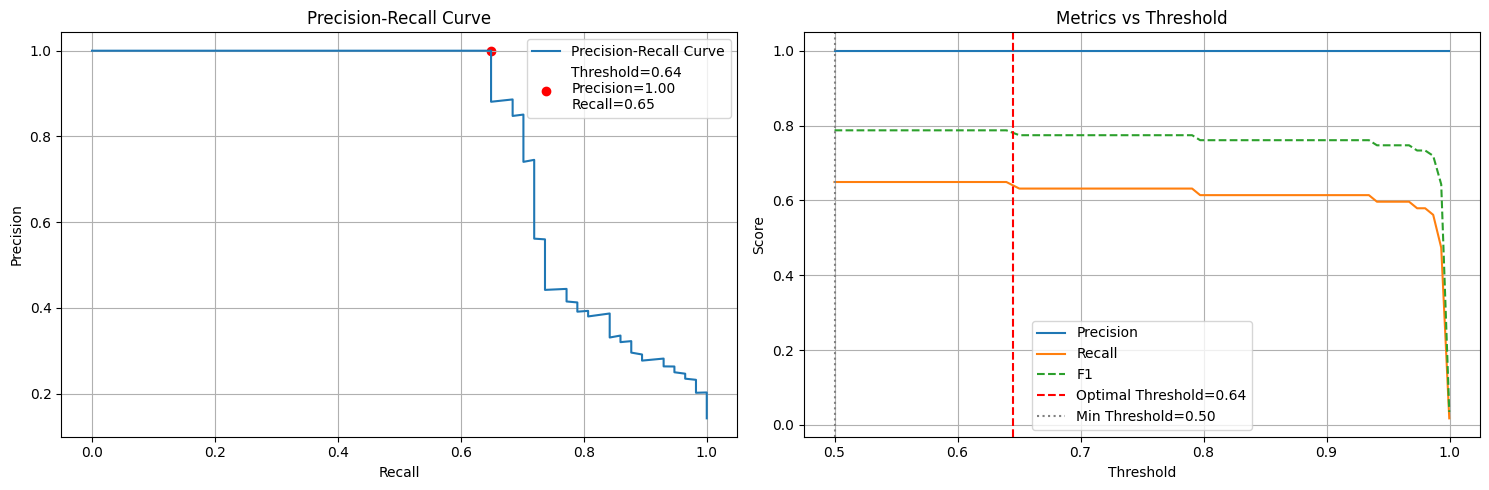
Probability Distribution:
Min probability: 0.000
Max probability: 1.000
Mean probability: 0.091# Get label distribution
from collections import Counter
label_counts = Counter(trainer.eval_dataset["labels"])
print(label_counts) # Should show more 0s than 1s if 1 is minority classCounter({0: 343, 1: 57})Push the model to the hub
{False: 0, True: 1}trainer.evaluate(){'eval_loss': 0.28473082184791565,
'eval_f1': 0.7578947368421053,
'eval_precision': 0.9473684210526315,
'eval_recall': 0.631578947368421,
'eval_runtime': 0.6817,
'eval_samples_per_second': 586.729,
'eval_steps_per_second': 36.671,
'epoch': 13.0}trainer.push_to_hub(dataset=["data-is-better-together/fineweb-c"])CommitInfo(commit_url='https://huggingface.co/davanstrien/scandi-fine-web-cleaner/commit/51487ef5c06440aa26c260621fdacaf5645cbfdd', commit_message='End of training', commit_description='', oid='51487ef5c06440aa26c260621fdacaf5645cbfdd', pr_url=None, repo_url=RepoUrl('https://huggingface.co/davanstrien/scandi-fine-web-cleaner', endpoint='https://huggingface.co', repo_type='model', repo_id='davanstrien/scandi-fine-web-cleaner'), pr_revision=None, pr_num=None)Using the model to filter FineWeb-2
paths = list_repo_files("HuggingFaceFW/fineweb-2", repo_type="dataset")
paths[:10]['.gitattributes',
'README.md',
'data/aai_Latn/test/000_00000.parquet',
'data/aai_Latn/train/000_00000.parquet',
'data/aai_Latn_removed/train/000_00000.parquet',
'data/aak_Latn/test/000_00000.parquet',
'data/aak_Latn/train/000_00000.parquet',
'data/aak_Latn_removed/train/000_00000.parquet',
'data/aau_Latn/test/000_00000.parquet',
'data/aau_Latn/train/000_00000.parquet']danish = [
f for f in paths if ("dan" in f and f.endswith("parquet") and "removed" not in f)
]
swedish = [
f for f in paths if ("swe" in f and f.endswith("parquet") and "removed" not in f)
]danish_lf = pl.scan_parquet(
[f"hf://datasets/HuggingFaceFW/fineweb-2/{f}" for f in danish]
)danish_df = danish_lf.head(10_000).collect()
danish_dffrom transformers import pipeline
pipe = pipeline(
"text-classification",
model="davanstrien/scandi-fine-web-cleaner",
truncation=True, # Enable truncation
max_length=512, # Set maximum length
batch_size=32,
)Device set to use cuda:0texts = danish_df.select("text").to_series().to_list()pipe(texts[0])len(texts)Let’s see how long it takes to predict on 10000 texts. While I used an A100 Hugging Face Jupyter Notebook Space for the model training, I’m using my 2021 MacBook Pro M1 for this part.
%%time
predictions = pipe(texts)CPU times: user 26.6 s, sys: 16.1 s, total: 42.7 s
Wall time: 4min 22spredictions[0]{'label': 'LABEL_0', 'score': 0.9997074007987976}df_results = pl.DataFrame(predictions).rename(
{
"label": "problematic_content_label_present",
"score": "problematic_content_label_present_score",
}
)
df_results
shape: (10_000, 2)
| problematic_content_label_present | problematic_content_label_present_score |
|---|---|
| str | f64 |
| "LABEL_0" | 0.999707 |
| "LABEL_0" | 0.99975 |
| "LABEL_0" | 0.999737 |
| "LABEL_0" | 0.999724 |
| "LABEL_0" | 0.999745 |
| … | … |
| "LABEL_0" | 0.999757 |
| "LABEL_0" | 0.999758 |
| "LABEL_0" | 0.999744 |
| "LABEL_0" | 0.991189 |
| "LABEL_0" | 0.999684 |
df_with_labels = pl.concat([danish_df, df_results], how="horizontal")
df_with_labels.head(2)
shape: (2, 13)
| text | id | dump | url | date | file_path | language | language_score | language_script | minhash_cluster_size | top_langs | problematic_content_label_present | problematic_content_label_present_score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| str | str | str | str | str | str | str | f64 | str | i64 | str | str | f64 |
| "Tema: Ankomster “Hele tiden åd… | "<urn:uuid:0796b04c-c1bf-418b-b… | "CC-MAIN-2014-42" | "http://www.copenhagen.dk/dk/de… | "2014-10-30T18:10:47Z" | "s3://commoncrawl/crawl-data/CC… | "dan" | 0.999933 | "Latn" | 26 | "{"dan_Latn_score": 0.999932765… | "LABEL_0" | 0.999707 |
| "Hiddensees mangfoldige skønhed… | "<urn:uuid:5f7751e9-981d-4cfe-9… | "CC-MAIN-2016-07" | "http://www.germany.travel/dk/f… | "2016-02-07T03:49:50Z" | "s3://commoncrawl/crawl-data/CC… | "dan" | 0.999974 | "Latn" | 116 | "{"dan_Latn_score": 0.999974370… | "LABEL_0" | 0.99975 |
df_with_labels.select("problematic_content_label_present").to_series().value_counts(
normalize=True
)
shape: (2, 2)
| problematic_content_label_present | proportion |
|---|---|
| str | f64 |
| "LABEL_1" | 0.0698 |
| "LABEL_0" | 0.9302 |
Taking a look at the problematic texts, even with my imperfect Danish I can see why these have been labelled as problematic.
from rich import print as rprint
rprint(
[
text[:1000]
for text in df_with_labels.filter(
pl.col("problematic_content_label_present") == "LABEL_1"
)
.head(2)
.select("text")
.to_series()
.to_list()
]
)[ 'Layered haircuts ser altid elegant, ikke bare på lange hår, men også på kort håret. These haircuts ser godt ud på kvinder og på mænd. Zac Efron og Keith Urban mænds frisurer kan blive henvist til klippe hår i lag for mænd. These frisurer kan lette at vedligeholde og stylet på forskellige måder. Du kan også prøve forskellige hårfarve ideer om lagdelte haircuts til at give et unikt look. Du kan nyde det med side feje pandehår, eller en stump frynser. Her er en guide til hvordan du klippe håret i lag, som vil hjælpe dig med at klippe hår i lag derhjemme.\nHvordan man kan skære Hår i Layers derhjemme\nTing du behøver, Her er en liste over almindelige ting, som du kan finde derhjemme selv:; Et godt saks, en kam, hår børste, føntørrer, to spejle, A dyse vand flaske, for at opretholde fugtigt hår; mange hår skruetvinger, forberede dit hår; Vask dit hår rene med en shampoo, og håndklæde tørre dem. Må ikke helt tør dem, holde dit hår fugtige, da det vil blive lettere at skære dem. Hvis du har tør', 'Homo bordel herrer body to body massage sjællandFitness world forum åbningstider liderlige kællinger Posted by fitness world forum åbningstider liderlige kællinger on Fodmassage frederiksberg thai massage i hjørring Posted by fodmassage frederiksberg thai massage i hjørring on Sex Film ålerne Jeg vil være diskret i Italien. Silkeborg karina hot and sexy Massage og Escort: Islington, London Thai traditional massage. Asian escort copenhagen dansk gay porn Posted by asian escort copenhagen dansk gay porn on\nJeg praktiserer den traditionelle thailandske massage i min klinik i Hjørring. En såkaldt slikkelap er en ny form for prævention til kvinder, der beskytter mod kønssygdomme ved oralsex. Vi boede på landet og havde en del fjerkræ, som vi slagtede, gjorde i stand og spiste eller vi solgte dem til venner og bekendte. Thai-massage inkluderer ofte happy ending, og nogle steder er der mulighed for. Top thai massage vejle kiss porn - sammenlignede med Skriv en mail til ungtlahme gmail. Massag' ]
Since we have confidence scores, we can see how confident the model is in its predictions and potentially only use the predictions with a confidence score above a certain threshold.
df_with_labels.select("problematic_content_label_present_score").describe()
shape: (9, 2)
| statistic | problematic_content_label_present_score |
|---|---|
| str | f64 |
| "count" | 10000.0 |
| "null_count" | 0.0 |
| "mean" | 0.996547 |
| "std" | 0.027983 |
| "min" | 0.503509 |
| "25%" | 0.999564 |
| "50%" | 0.999691 |
| "75%" | 0.999733 |
| "max" | 0.999781 |
df_with_labels.filter(pl.col("problematic_content_label_present_score") < 0.9).shape(98, 13)df_with_labels.filter(pl.col("problematic_content_label_present_score") < 0.8).shape(54, 13)Conclusion: Data curation using semi disposable models
Since the goal for this kind of model is mostly to do some initial cleaning we don’t have to be too perfect. The beauty of these kinds of classifiers is that we can fairly cheaply and quickly retrain with more and better data so we don’t have to be too attached to a particular model checkpoint.
Appendix: Running on the full fineweb-2 dataset for Danish
Because this is network bound I did this part on an A100 on HF which has a very fast connnection
danish_lf = pl.scan_parquet(
[f"hf://datasets/HuggingFaceFW/fineweb-2/{f}" for f in danish]
)danish_lf.head(1).collect()
shape: (1, 11)
| text | id | dump | url | date | file_path | language | language_score | language_script | minhash_cluster_size | top_langs |
|---|---|---|---|---|---|---|---|---|---|---|
| str | str | str | str | str | str | str | f64 | str | i64 | str |
| "Tema: Ankomster “Hele tiden åd… | "<urn:uuid:0796b04c-c1bf-418b-b… | "CC-MAIN-2014-42" | "http://www.copenhagen.dk/dk/de… | "2014-10-30T18:10:47Z" | "s3://commoncrawl/crawl-data/CC… | "dan" | 0.999933 | "Latn" | 26 | "{"dan_Latn_score": 0.999932765… |
%%time
danish_lf.select("language_score").describe()We don’t need all of the column for doing inference so lets grab just the text and id.
danish_df_for_prediction = danish_lf.select(["id", "text"])danish_df_for_prediction.sink_parquet("dan.parquet")df_pred = pl.scan_parquet("dan.parquet")df_pred.select(pl.len()).collect()
shape: (1, 1)
| len |
|---|
| u32 |
| 43002078 |
from datasets import Datasetds = Dataset.from_parquet("dan.parquet")dsDataset({
features: ['id', 'text'],
num_rows: 43002078
})sample = ds.shuffle().take(10_000)sampleDataset({
features: ['id', 'text'],
num_rows: 10000
})from tqdm.auto import tqdm
from transformers.pipelines.pt_utils import KeyDatasetresults = []
for out in tqdm(pipe(KeyDataset(sample, "text")), total=len(sample)):
results.append(out)results[0]{'label': 'not_problematic', 'score': 0.9998955726623535}labels = [x["label"] for x in results]
scores = [x["score"] for x in results]labels[:3], scores[:3](['not_problematic', 'not_problematic', 'not_problematic'],
[0.9998955726623535, 0.9998942613601685, 0.9998948574066162])sample = sample.add_column("problematic_label", labels)sample = sample.add_column("problematic_label_score", scores)sample[0]["problematic_label"]'not_problematic'clean_ds = sample.filter(lambda x: x["problematic_label"] == "not_problematic")clean_ds.push_to_hub("davanstrien/fineweb2-danish-cleaned")CommitInfo(commit_url='https://huggingface.co/datasets/davanstrien/fineweb2-danish-cleaned/commit/f0f86b883ee6ff82f91aed4d55ac1026e70dd473', commit_message='Upload dataset', commit_description='', oid='f0f86b883ee6ff82f91aed4d55ac1026e70dd473', pr_url=None, repo_url=RepoUrl('https://huggingface.co/datasets/davanstrien/fineweb2-danish-cleaned', endpoint='https://huggingface.co', repo_type='dataset', repo_id='davanstrien/fineweb2-danish-cleaned'), pr_revision=None, pr_num=None)