from datasets import load_dataset
ds = load_dataset("biglam/doab-metadata-extraction", split="train")
print(f"Total books: {len(ds)}")Total books: 8086We’ll evaluate how well different AI models can extract metadata — title, subtitle, publisher, year, ISBN — from scanned academic book pages. This is a concrete example of the structured extraction pattern from earlier chapters, and it demonstrates two different scoring approaches: rules-based and LLM-as-judge.
We’ll use the Inspect AI framework to structure the evaluation, keeping things reproducible and comparable across models.
We’ll use the DOAB Metadata Extraction dataset from Hugging Face. This contains page images and ground truth metadata for 9,363 open access academic books from the Directory of Open Access Books.
Each record includes scanned page images (title pages, copyright pages) along with known metadata: title, subtitle, publisher, publication year, and ISBN. This gives us a clear ground truth to evaluate against.
from datasets import load_dataset
ds = load_dataset("biglam/doab-metadata-extraction", split="train")
print(f"Total books: {len(ds)}")Total books: 8086Let’s look at an example. Each book has page images we can feed to a VLM, and metadata fields we can check the model’s answers against:
example = ds[0]
print(f"Title: {example['title']}")
print(f"Publisher: {example['publisher']}")
print(f"Year: {example['publication_year']}")
print(f"Pages available: {len(example['page_images'])}")
# Show the first page
example['page_images'][0]Title: Migration in the Southern Balkans: From Ottoman Territory to Globalized Nation States
Publisher: Springer Nature
Year: 2015
Pages available: 8
For our evaluation, we’ll sample 50 books and use their first few pages as input to the model. The known metadata serves as our ground truth — the answers we’re checking against.
Inspect AI is a framework for evaluating language models. It provides a clean structure for defining evaluations with three core concepts:
Here’s the full evaluation task for our metadata extraction. It loads book page images, sends them to a VLM with an extraction prompt, and uses an LLM as judge to score the results:
import io
import json
import base64
from typing import List
from datasets import load_dataset
from inspect_ai import Task, task
from inspect_ai.dataset import Sample, MemoryDataset
from inspect_ai.model import ChatMessageUser, ContentImage, ContentText
from inspect_ai.solver import generate
from inspect_ai.scorer import model_graded_qa
EXTRACTION_PROMPT = """Extract the following metadata from this book \
and return ONLY a JSON object:
{
"title": "Main title of the book",
"subtitle": "Subtitle if present, otherwise null",
"publisher": "Publisher name",
"publication_year": "Year of publication (e.g., 2015)",
"isbn": "ISBN number (any format)"
}
Look at all the pages provided. The title and subtitle are usually on \
the first page. Publisher information and ISBN are often on the copyright \
page or title page verso.
Return ONLY the JSON object, no markdown formatting, no additional text."""The dataset loading converts each book into an Inspect AI Sample — a multimodal input (prompt + page images) paired with a ground truth target:
def load_doab_samples(sample_size: int = 50, seed: int = 42) -> List[Sample]:
"""Load DOAB dataset as Inspect AI samples with page images."""
dataset = load_dataset(
"biglam/doab-metadata-extraction", split="train"
)
dataset = dataset.shuffle(seed=seed).select(range(sample_size))
samples = []
max_pages = 5 # title page, copyright page, etc.
for example in dataset:
title = example.get("title")
page_images = example.get("page_images", [])
if not title or not page_images:
continue
# Build multimodal content: prompt + page images
content = [ContentText(text=EXTRACTION_PROMPT)]
for img in page_images[:max_pages]:
buffered = io.BytesIO()
img.save(buffered, format="PNG")
image_base64 = base64.b64encode(
buffered.getvalue()
).decode("utf-8")
content.append(
ContentImage(
image=f"data:image/png;base64,{image_base64}"
)
)
# Ground truth metadata
ground_truth = {
"title": title,
"subtitle": example.get("subtitle"),
"publisher": example.get("publisher"),
"publication_year": example.get("publication_year"),
"isbn": example.get("isbn"),
}
samples.append(Sample(
input=[ChatMessageUser(content=content)],
target=json.dumps(ground_truth, indent=2),
metadata={"record_id": example["record_id"]},
))
return samplesThe task itself is remarkably concise — Inspect handles the orchestration:
@task
def doab_metadata_eval(sample_size: int = 50, seed: int = 42):
"""Evaluate metadata extraction from academic book pages."""
samples = load_doab_samples(
sample_size=sample_size, seed=seed
)
return Task(
dataset=MemoryDataset(samples),
solver=[generate()],
scorer=model_graded_qa(
template=GRADING_TEMPLATE, # defined below
instructions=GRADING_INSTRUCTIONS,
partial_credit=True,
),
)To run this evaluation from the command line:
inspect eval evaluating_doab.py \
--model 'hf-inference-providers/Qwen/Qwen3-VL-8B-Instruct' \
-T sample_size=50The key design choice here is the scorer — how do we decide if the model’s output is correct? That’s worth discussing in detail.
The simplest approach is deterministic: write code that compares the model’s output against the ground truth. For title extraction, we built a custom scorer that normalizes both strings and checks for matches:
from inspect_ai.scorer import Score, scorer, accuracy, mean
def normalize_title(text: str) -> str:
"""Normalize title for comparison."""
if not text:
return ""
text = text.lower().strip()
# Normalize quotes and dashes
text = text.replace('\u201c', '"').replace('\u201d', '"')
text = text.replace('\u2018', "'").replace('\u2019', "'")
text = text.replace('\u2013', '-').replace('\u2014', '-')
# Collapse whitespace, strip trailing punctuation
text = " ".join(text.split())
text = text.rstrip(".,;:-")
return text
def titles_match(predicted: str, ground_truth: str) -> tuple[bool, str]:
"""Flexible title matching."""
pred_norm = normalize_title(predicted)
gt_norm = normalize_title(ground_truth)
if not pred_norm or not gt_norm:
return False, "no_match"
if pred_norm == gt_norm:
return True, "exact"
# Model included subtitle — still correct
if gt_norm in pred_norm:
return True, "gt_in_pred"
# Model truncated — still acceptable
if pred_norm in gt_norm:
return True, "pred_in_gt"
return False, "no_match"
@scorer(metrics=[accuracy(), mean()])
def title_scorer():
"""Score title extraction with flexible matching."""
async def score(state, target):
if not state.output or not state.output.completion:
return Score(
value=0.0, answer=None,
explanation="No output generated",
)
predicted = state.output.completion.strip()
ground_truth = (
target.text.strip()
if hasattr(target, "text")
else str(target).strip()
)
is_match, match_type = titles_match(predicted, ground_truth)
return Score(
value=1.0 if is_match else 0.0,
answer=predicted,
explanation=match_type,
)
return scoreThis scorer is fast, free, and deterministic — you’ll get the same result every time. It works well for title extraction because titles are relatively unambiguous strings. The flexible matching handles common edge cases: a model that returns “The History of Science: A Very Short Introduction” when the ground truth is just “The History of Science” still gets credit.
But what about fields where string matching breaks down? A model might extract "OUP" where the ground truth says "Oxford University Press". Or it might format an ISBN as "978-0-19-876543-2" while the ground truth has "9780198765432". These are semantically correct but would fail any rules-based comparison.
This is where an LLM judge becomes valuable. Instead of writing matching rules for every field and every edge case, you describe what “correct” means and let another model evaluate:
GRADING_TEMPLATE = """You are evaluating metadata extraction \
from academic book pages.
**Ground Truth Metadata:**
{criterion}
**Model's Extracted Metadata:**
{answer}
Compare the extracted metadata against ground truth for these fields:
- title: Should match (allow minor variations)
- subtitle: Should match if present in ground truth
- publisher: Should match (allow common abbreviations)
- publication_year: Must match exactly
- isbn: Any valid ISBN matching ground truth counts
{instructions}
"""
GRADING_INSTRUCTIONS = """Evaluate the overall extraction quality:
- GRADE: C (Correct) - Essential metadata captured correctly \
(title + year + at least one other field)
- GRADE: P (Partial) - Some fields correct, others wrong or missing
- GRADE: I (Incorrect) - Mostly incorrect or critical fields wrong
Provide brief reasoning, then end with exactly: \
GRADE: C, GRADE: P, or GRADE: I
"""In Inspect AI, using this is a one-liner — the model_graded_qa scorer handles the orchestration:
scorer = model_graded_qa(
template=GRADING_TEMPLATE,
instructions=GRADING_INSTRUCTIONS,
partial_credit=True, # C=1.0, P=0.5, I=0.0
)The trade-off is clear: LLM-as-judge scoring costs money (you’re running a second model for every evaluation) and isn’t perfectly deterministic. But it handles the messy reality of metadata comparison far better than string matching.
Start with LLM-as-judge unless your task has very clean, unambiguous answers. It’s more forgiving of formatting differences and handles the kinds of semantic equivalences that are common in metadata (abbreviations, reordering, alternate spellings). You can always add rules-based scoring later for fields where you want deterministic results — like title matching or year extraction.
We ran this evaluation across 6 models using two approaches: VLM (sending page images directly to vision-language models) and text-only (extracting text first, then sending it to a language model). Each evaluation used 50 books.
import pandas as pd
import matplotlib.pyplot as plt
title_results = pd.DataFrame([
{"Model": "Qwen3-VL-30B-A3B", "Approach": "VLM", "Params (B)": 30, "Accuracy": 0.98},
{"Model": "Qwen3-VL-8B", "Approach": "VLM", "Params (B)": 8, "Accuracy": 0.98},
{"Model": "GLM-4.6V-Flash", "Approach": "VLM", "Params (B)": 9, "Accuracy": 0.96},
{"Model": "Qwen3-VL-8B", "Approach": "Text", "Params (B)": 8, "Accuracy": 0.94},
{"Model": "gpt-oss-20b", "Approach": "Text", "Params (B)": 20, "Accuracy": 0.70},
{"Model": "Olmo-3-7B", "Approach": "Text", "Params (B)": 7, "Accuracy": 0.68},
{"Model": "Qwen3-4B", "Approach": "Text", "Params (B)": 4, "Accuracy": 0.68},
])
colors = {"VLM": "tab:blue", "Text": "tab:orange"}
fig, axes = plt.subplots(2, 1, figsize=(8, 9))
# Bar chart of individual models
ax1 = axes[0]
title_sorted = title_results.sort_values("Accuracy", ascending=True)
bars = ax1.barh(
title_sorted["Model"] + " (" + title_sorted["Approach"] + ")",
title_sorted["Accuracy"],
color=[colors[a] for a in title_sorted["Approach"]],
)
ax1.set_xlabel("Accuracy")
ax1.set_title("Title Extraction by Model")
ax1.set_xlim(0, 1.1)
ax1.axvline(x=0.9, color="green", linestyle="--", alpha=0.5, label="90% threshold")
for bar, val in zip(bars, title_sorted["Accuracy"]):
ax1.text(val + 0.01, bar.get_y() + bar.get_height() / 2, f"{val:.0%}", va="center", fontsize=10)
ax1.legend()
# Scatter: param size vs accuracy
ax2 = axes[1]
for approach in ["VLM", "Text"]:
subset = title_results[title_results["Approach"] == approach]
ax2.scatter(subset["Params (B)"], subset["Accuracy"], s=150, alpha=0.7, c=colors[approach], label=approach)
for _, row in subset.iterrows():
ax2.annotate(row["Model"], (row["Params (B)"], row["Accuracy"]), xytext=(5, 5), textcoords="offset points", fontsize=9)
ax2.set_xlabel("Parameter Size (Billions)")
ax2.set_ylabel("Accuracy")
ax2.set_title("Performance vs Model Size")
ax2.set_ylim(0.5, 1.05)
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()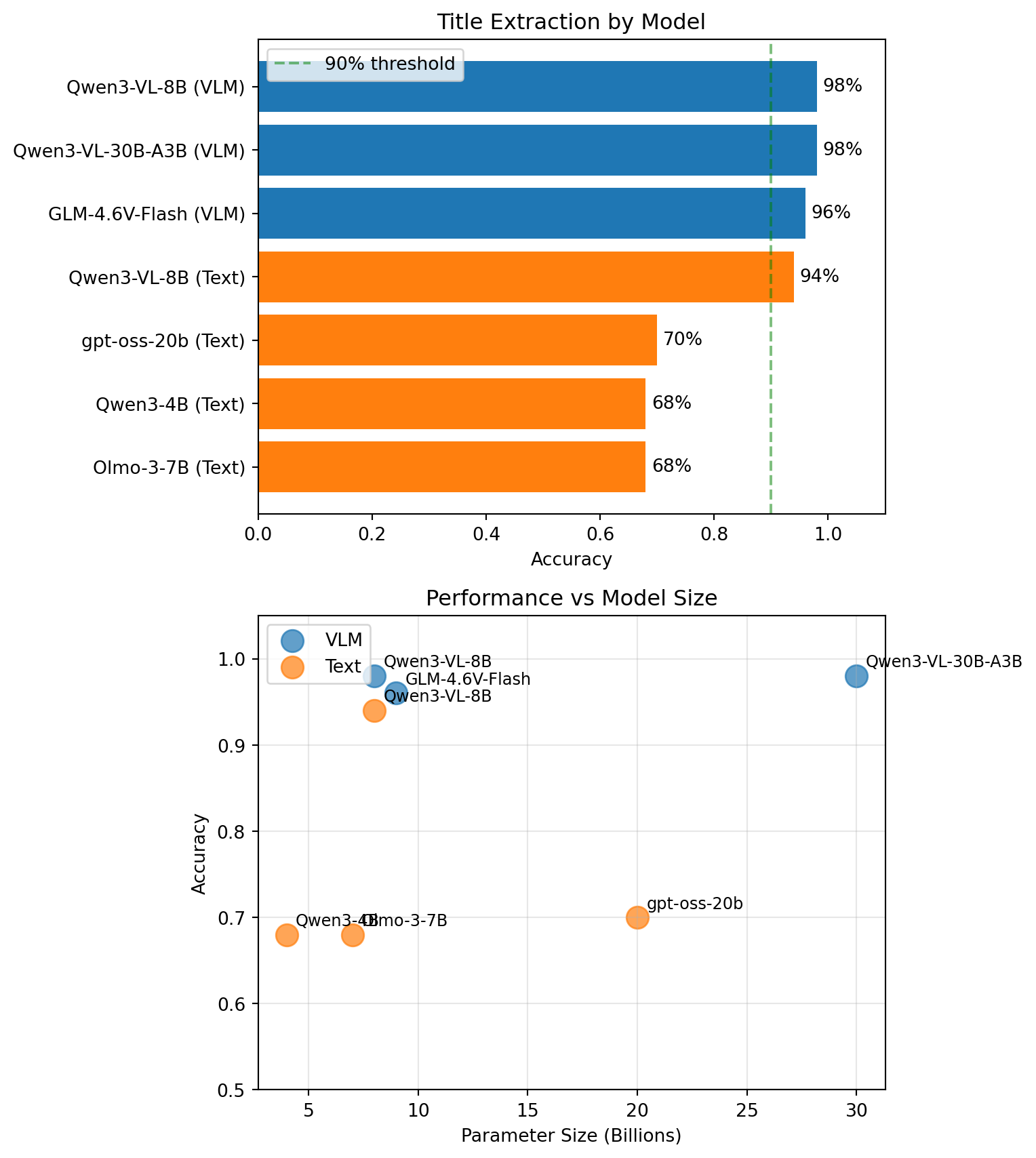
The VLM approach is clearly superior for title extraction — models that can see the title page directly achieve 96–98% accuracy, while text-only models that rely on pre-extracted text score lower and more variably.
The standout finding: even an 8B parameter VLM matches a 30B model on this task. For straightforward extraction from well-formatted pages, you don’t necessarily need the largest model available. The scatter plot makes this clear — there’s no consistent relationship between model size and accuracy. What matters more is whether the model can see the page directly (VLM) or is working from pre-extracted text.
metadata_results = pd.DataFrame([
{"Model": "GLM-4.6V-Flash", "Approach": "VLM", "Params (B)": 9, "Score": 0.81},
{"Model": "Qwen3-VL-30B-A3B", "Approach": "VLM", "Params (B)": 30, "Score": 0.80},
{"Model": "Qwen3-VL-8B", "Approach": "VLM", "Params (B)": 8, "Score": 0.78},
{"Model": "gpt-oss-20b", "Approach": "Text", "Params (B)": 20, "Score": 0.75},
{"Model": "Qwen3-VL-8B", "Approach": "Text", "Params (B)": 8, "Score": 0.75},
{"Model": "Qwen3-4B", "Approach": "Text", "Params (B)": 4, "Score": 0.69},
{"Model": "Olmo-3-7B", "Approach": "Text", "Params (B)": 7, "Score": 0.65},
])
fig, axes = plt.subplots(2, 1, figsize=(8, 9))
# Bar chart
ax1 = axes[0]
meta_sorted = metadata_results.sort_values("Score", ascending=True)
bars = ax1.barh(
meta_sorted["Model"] + " (" + meta_sorted["Approach"] + ")",
meta_sorted["Score"],
color=[colors[a] for a in meta_sorted["Approach"]],
)
ax1.set_xlabel("Score")
ax1.set_title("Full Metadata Extraction by Model")
ax1.set_xlim(0, 1.1)
for bar, val in zip(bars, meta_sorted["Score"]):
ax1.text(val + 0.01, bar.get_y() + bar.get_height() / 2, f"{val:.2f}", va="center", fontsize=10)
# Approach comparison
ax2 = axes[1]
approach_stats = metadata_results.groupby("Approach")["Score"].agg(["mean", "std", "count"])
bars = ax2.bar(
approach_stats.index,
approach_stats["mean"],
yerr=approach_stats["std"],
capsize=5,
alpha=0.7,
color=[colors[a] for a in approach_stats.index],
)
ax2.set_ylabel("Mean Score")
ax2.set_title("VLM vs Text-Only")
ax2.set_ylim(0, 1.0)
for i, (approach, row) in enumerate(approach_stats.iterrows()):
ax2.annotate(f'{row["mean"]:.2f}\n(n={int(row["count"])})', (i, row["mean"] + row["std"] + 0.03), ha="center", fontsize=12)
plt.tight_layout()
plt.show()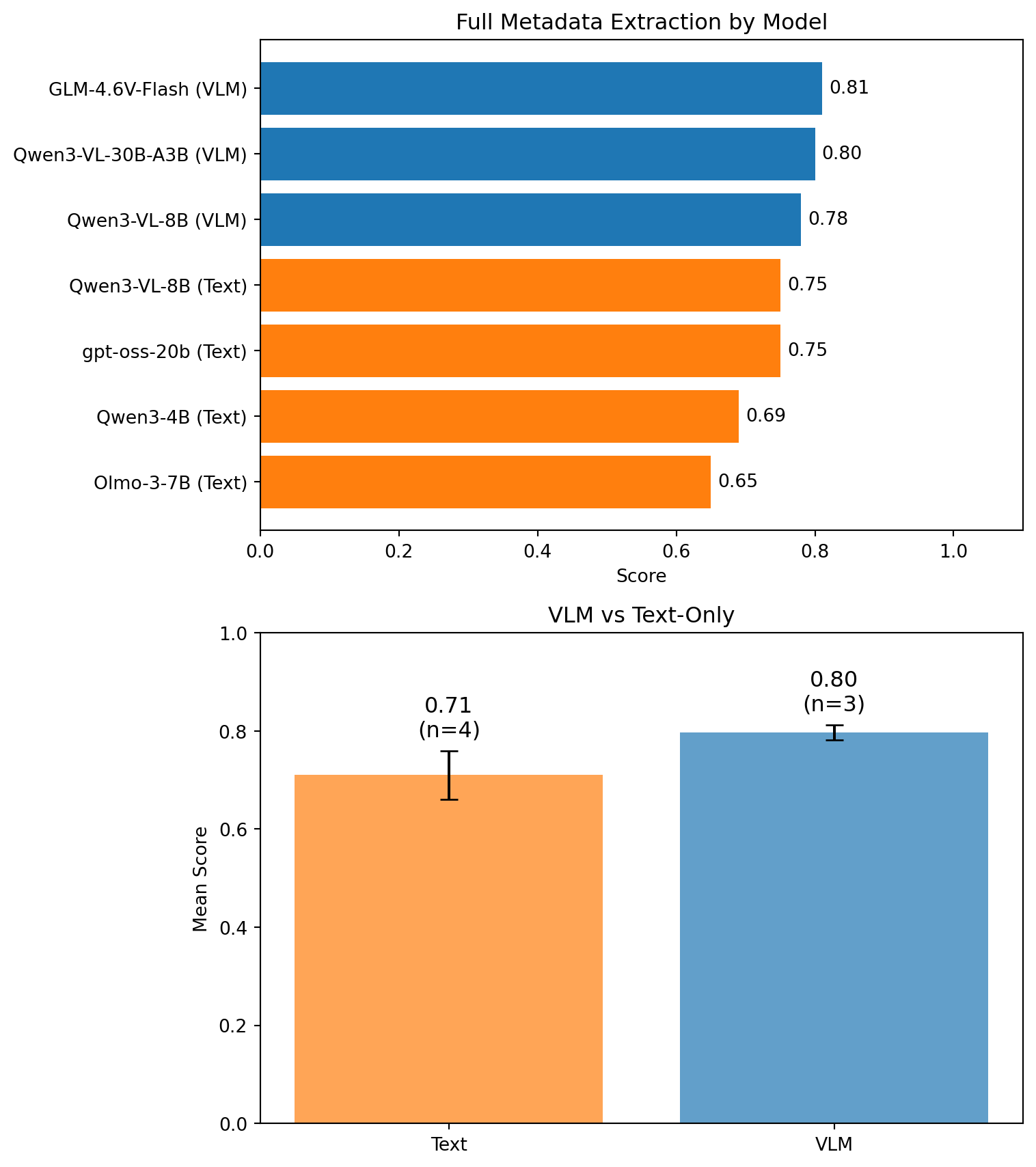
Full metadata extraction is harder — the model needs to find and correctly extract five different fields from multiple pages. Scores of 0.78–0.81 mean most extractions are at least partially correct, with many fully correct. The gap between VLM and text approaches is smaller here, suggesting that some fields (like ISBN or publisher) are reliably present in the text regardless of how it was extracted.
The evaluation structure we’ve walked through is general enough to adapt to any extraction task:
Assemble a ground truth dataset — even 50 manually verified examples gives you useful signal. Publish it on Hugging Face so others can reproduce your results.
Define your extraction task as an Inspect AI Task — a dataset, a solver (usually just generate()), and a scorer.
Choose your scorer — rules-based for fields with unambiguous answers, LLM-as-judge for fields where semantic equivalence matters.
Run across multiple models — you might be surprised which ones perform best for your specific collection. Use Hugging Face Inference Providers to try models without managing infrastructure.
Share your results — the Community Evals program on Hugging Face lets you publish evaluation benchmarks alongside your dataset, so others can compare their models on your task.